InnoDB如何引擎通过Next-Key Lock部分解决幻读
1. 幻读问题概述
幻读是数据库并发事务中最棘手的一类问题。它指在同一事务内,连续执行两次相同的查询语句,第二次查询所返回的结果集与第一次查询的结果集不同。具体表现为:新增了符合查询条件的行。
示例场景
1 | -- 事务A |
InnoDB如何引擎通过Next-Key Lock部分解决幻读
幻读是数据库并发事务中最棘手的一类问题。它指在同一事务内,连续执行两次相同的查询语句,第二次查询所返回的结果集与第一次查询的结果集不同。具体表现为:新增了符合查询条件的行。
1 | -- 事务A |
在并发环境下,多个事务同时操作数据库时会产生各种并发问题。如果不进行隔离控制,可能会导致数据的不一致性。主要会出现以下问题:
堆是一种特殊的完全二叉树,分为大根堆(大顶堆)和小根堆(小顶堆):
堆通常用数组实现,对于数组中的第i个节点:
下面是一个小根堆的Java实现:
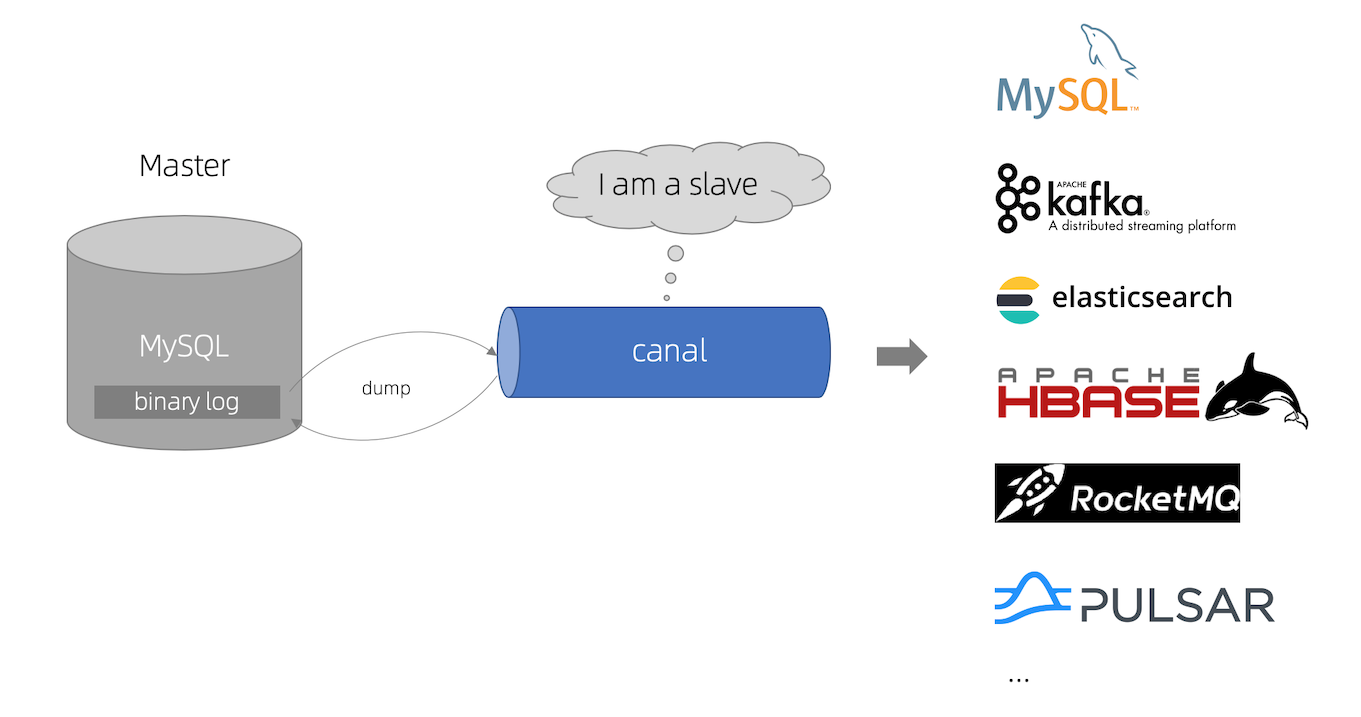
**canal [kə’næl]**,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
先查询缓存,如果查询失败,那么去查询DB,之后重建缓存,基本上不存在异议。
先更新DB还是先更新缓存?是更新缓存还是删除缓存?在常规情况下,怎么操作都可以,但一旦面对高并发场景,就值得细细思量了。
线程A:更新数据库(第1s)——> 更新缓存(第10s)
Java 阻塞队列的历史可以追溯到 JDK1.5 版本,当时 Java 平台增加了 java.util.concurrent,即我们常说的 JUC 包,其中包含了各种并发流程控制工具、并发容器、原子类等。这其中自然也包含了我们这篇文章所讨论的阻塞队列。
为了解决高并发场景下多线程之间数据共享的问题,JDK1.5 版本中出现了 ArrayBlockingQueue 和 LinkedBlockingQueue,它们是带有生产者-消费者模式实现的并发容器。其中,ArrayBlockingQueue 是有界队列,即添加的元素达到上限之后,再次添加就会被阻塞或者抛出异常。而 LinkedBlockingQueue 则由链表构成的队列,正是因为链表的特性,所以 LinkedBlockingQueue 在添加元素上并不会向 ArrayBlockingQueue 那样有着较多的约束,所以 LinkedBlockingQueue 设置队列是否有界是可选的(注意这里的无界并不是指可以添加任务数量的元素,而是说队列的大小默认为 Integer.MAX_VALUE,近乎于无限大)。
ConcurrentHashMap 为什么不允许key和value为null
在Java中,ConcurrentHashMap是一种线程安全的哈希表实现,广泛用于并发编程场景中。与传统的HashMap不同,ConcurrentHashMap不允许null键或null值。这种设计并非随意而为,而是经过深思熟虑的决定。
null键的歧义在ConcurrentHashMap中,如果允许null键,当我们调用map.get(null)时,返回null意味着什么?
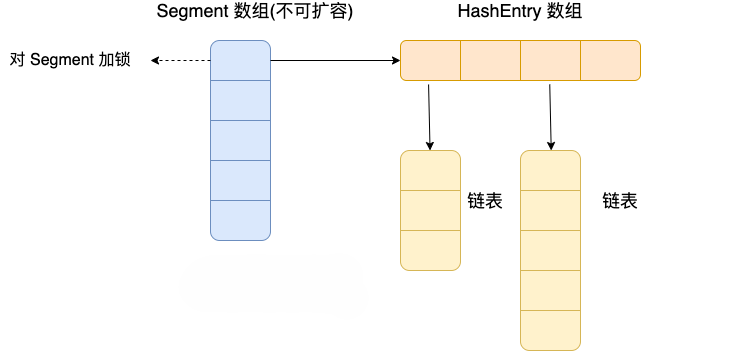
Java 7 中 ConcurrentHashMap 的存储结构如上图,ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦初始化就不能改变,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。
《阿里巴巴 Java 开发手册》的描述如下:
判断所有集合内部的元素是否为空,使用
isEmpty()方法,而不是size()==0的方式。
这是因为 isEmpty() 方法的可读性更好,并且时间复杂度为 O(1)。
绝大部分我们使用的集合的 size() 方法的时间复杂度也是 O(1),不过,也有很多复杂度不是 O(1) 的,比如 java.util.concurrent 包下的 ConcurrentLinkedQueue。ConcurrentLinkedQueue 的 isEmpty() 方法通过 first() 方法进行判断,其中 first() 方法返回的是队列中第一个值不为 null 的节点(节点值为null的原因是在迭代器中使用的逻辑删除)