MySQL 索引
定义
索引是对数据库表中一列或者多列的值进行排序的结构。
目的
数据库索引好比一本书的目录,提高查询效率。但是为表设置索引要付出相应的代价:
- 增加了数据库的存储空间
- 在插入和修改时需花费更多的时间(因为索引也要随之变动)
分类
1. 聚集索引
索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储其真实的数据行,不再有另外单独的数据页。
2. 非聚集索引
表数据存储顺序与索引顺序无关。对于非聚集索引,叶子结点包含索引字段值和数据页数据行的地址,其行数量与数据表中行数量一致。
注意:一个表中只有一个聚集索引,但是可以有多个非聚集索引。
3. 唯一索引
不允许具有索引值相同的行,但是可以为 NULL,不能有多个 NULL。
4. 主键索引
是唯一索引的特殊类型。数据库表中经常有一列或多列组合,其值唯一标识表中的每一行,该列称为表的主键。
在数据库中为表定义主键将自动创建主键索引。
索引存储结构
B 树
对于 m 阶 B 树,有如下性质:
根节点至少有 2 个孩子节点
树中每个节点最多含有 m 个孩子(m >= 2)
除根节点、叶子节点外其他节点至少有 ceil(m/2) 个孩子
所有叶子节点都在同一层
假设每个非终端节点中包含 n 个关键字信息,其中
a)Ki(i=1..n)为关键字,being且找顺序升序排序 K(i-1) < Ki
b)关键字的个数 n 必须满足:ceil(m/2)-1 <= n <= (m-1)
c)非叶子节点的指针:P[1],P[2],… ,P[M];其中 P[1] 指向关键字小于 K[1] 的子树,P[M] 指向关键字大于 K[M-1] 的子树,其他 P[i] 关键字属于(K[i-1],K[i]) 的子树
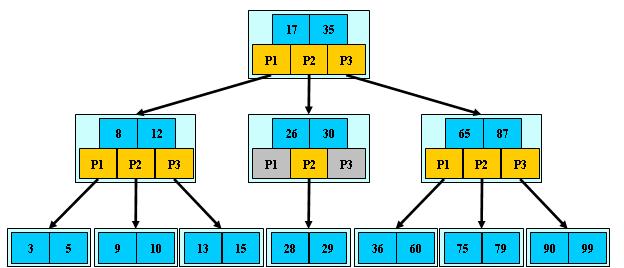
B+ 树
B+ 树是 B 树的变体,其定义基本与 B 树相同,除了:
非叶子节点的子树指针和关键字个数相同
非叶子节点的子树指针 P[i],指向关键字值 [K[i],K[i+1]) 的子树
非叶子节点仅用来索引,数据都保存在叶子节点
所有叶子节点均有一个链指针指向下一个叶子节点
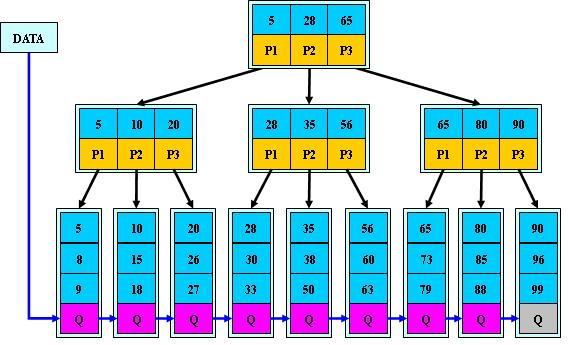
数据库系统普遍采用 B+ 树作为索引结构,主要有以下原因:
B+ 树的磁盘读写代价更低
因为非叶子结点只存储索引信息,其内部节点相同 B 树更小,如果把 key 存入同一盘块中,盘块所能包含的 key 越多,一次性读入内存中需要查找的 key 就越多,相对来说磁盘的 I/O次数就减少了。
举个例子:假设磁盘中的一个盘块容纳 16 字节,而一个 key 占 2 字节,一个 key 具体信息指针占 2 字节。一棵 9 阶 B 树(一个结点最多 8 个关键字)的内部结点需要 2 ( (8*(2+2) / 16 = 2)个盘块。B+ 树内部结点只需要 1 (8 * 2 / 16 = 1)个盘块。当需要把内部结点读入内存中的时候,B 树就比 B+ 树多 1 次盘块查找时间。
B+ 树的查询效率更加稳定
由于非叶子结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B+ 树更有利于对数据库的扫描
B+ 树只要遍历叶子结点就可以遍历到所有数据。
HASH
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似 B+ 树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应位置,速度非常快。
哈希索引底层的数据结构是哈希表,能以 O(1) 时间进行查找,但是失去了有序性;因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快。
哈希索引的不足:
- 无法用于排序与分组
- 只支持精确查找,无法用于部分查找和范围查找
- 不能避免全表扫描
- 遇到大量 Hash 冲突的情况效率会大大降低
索引的物理存储
MySQL 索引使用的是 B 树中的 B+ 树,但索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
MyISAM 索引存储机制
MyISAM 引擎使用 B+ 树作索引结构,叶子节点的 data 域存放的是数据记录的地址,所有索引均是非聚集索引。
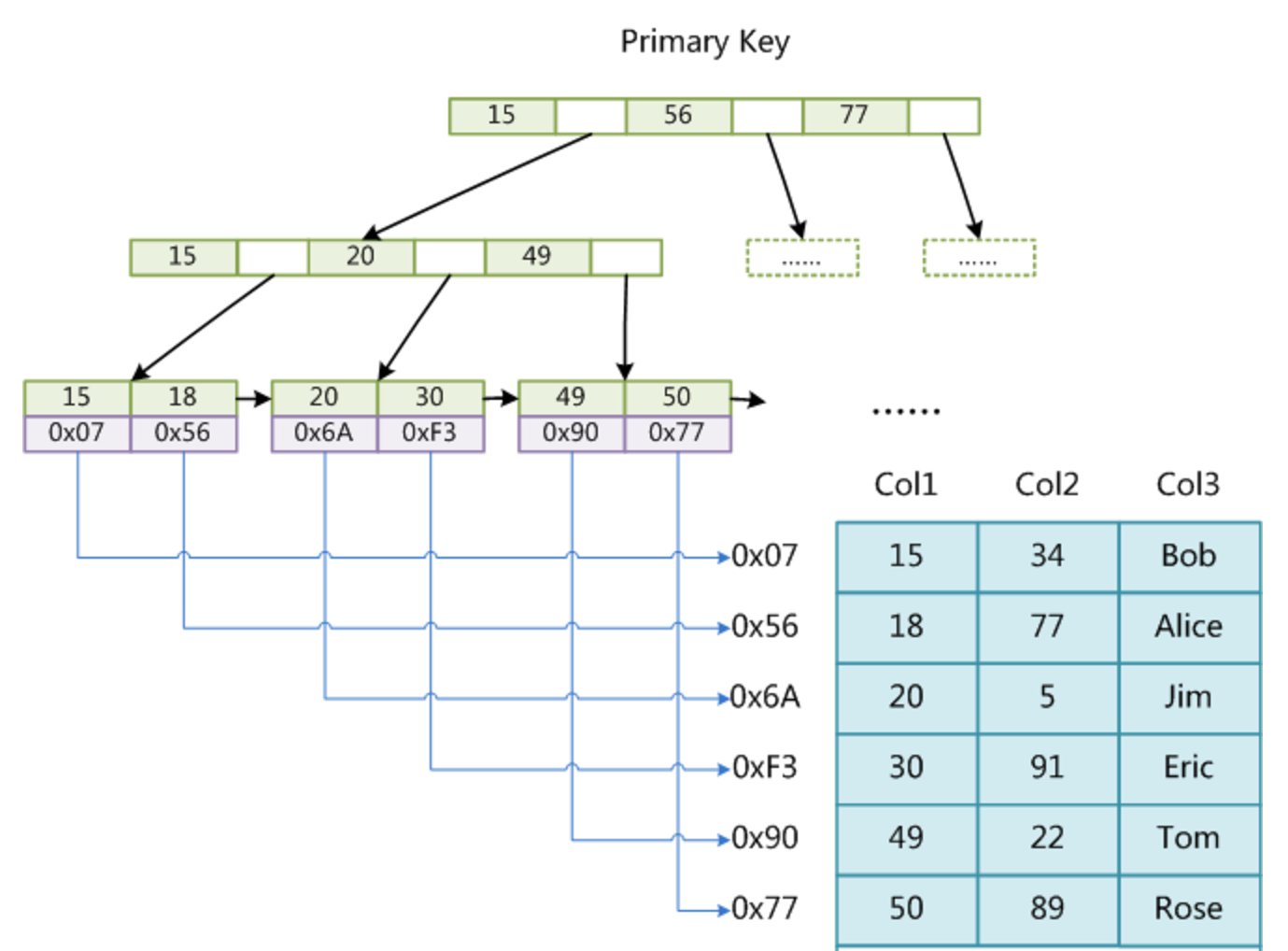
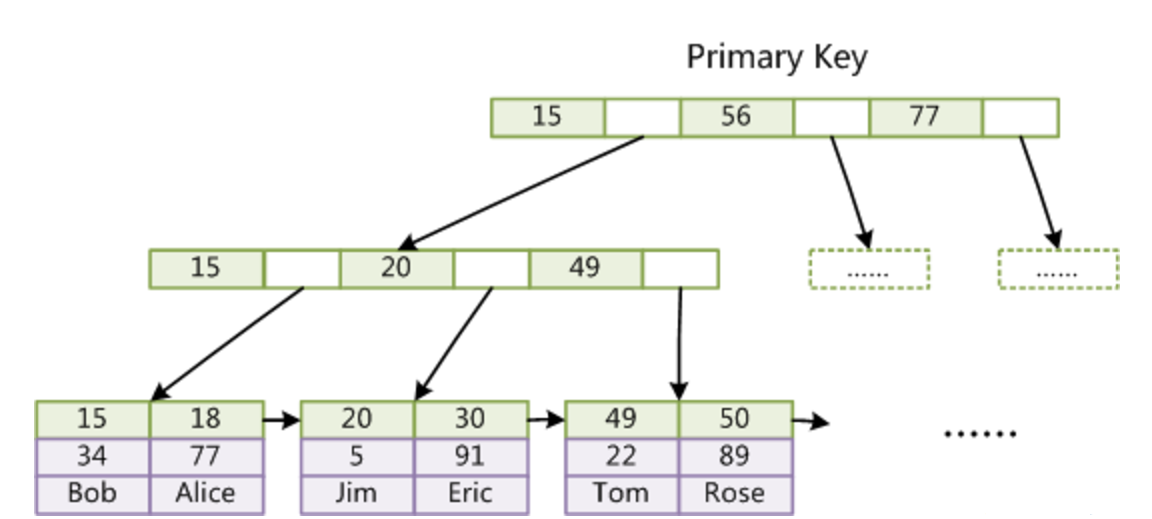
上图是一个 MyISAM 表的主索引(Primary key)示意图。
假设该表一共有三列,以 Col1 为主键。MyISAM 的索引文件仅仅保存数据记录的地址。
在 MyISAM 中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求 key 是唯一的,而辅助索引的 key 可以重复。如果在 Col2 上建立一个辅助索引,则该辅助索引的结构如下:
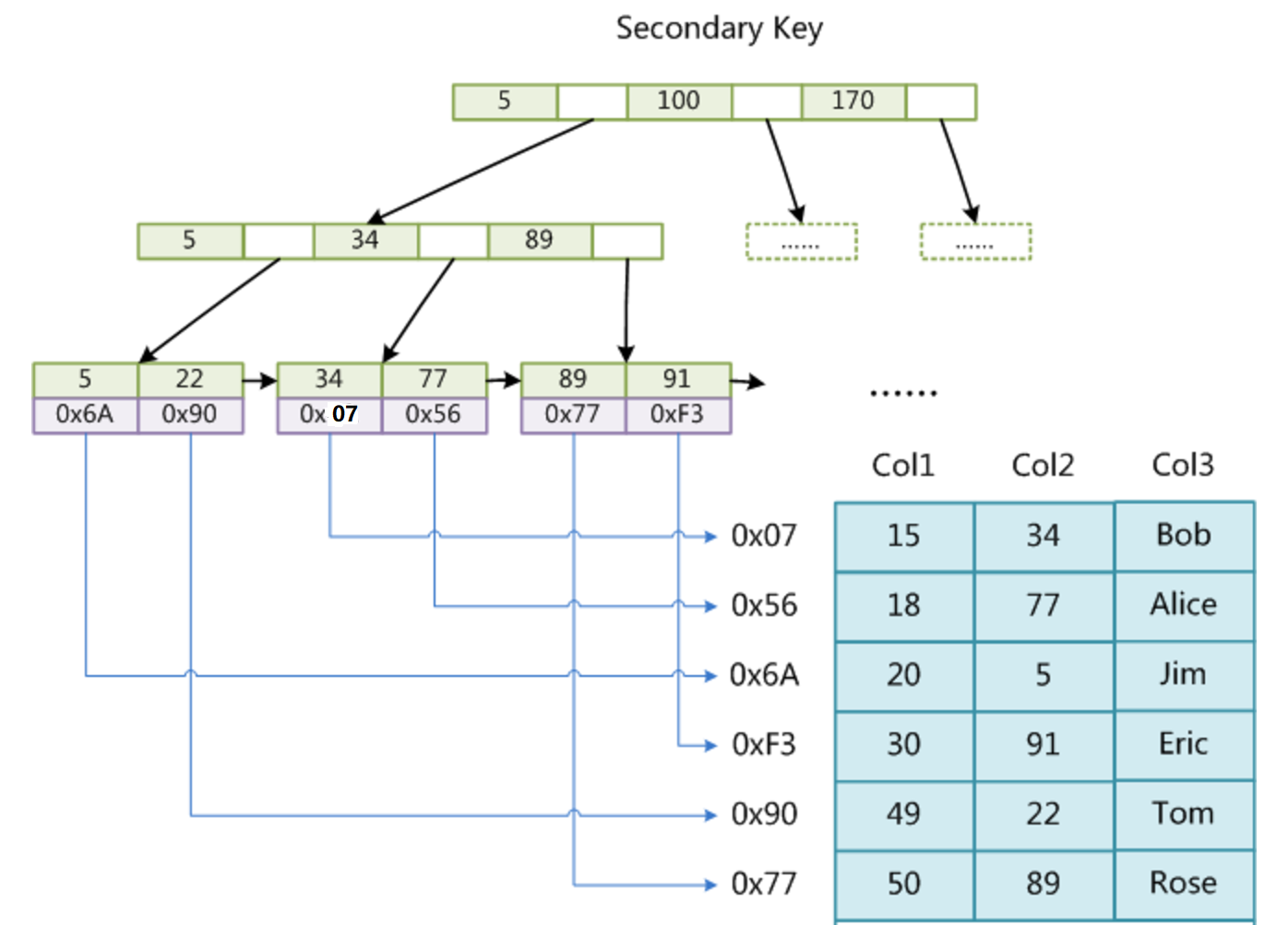
同样也是一棵 B+ 树,data 域保存数据记录的地址。
MyISAM 中首先按照 B+ 树搜索算法搜索索引,如果指定的 key 存在,则取出其 data 域的值,然后以 data 域的值为地址,读取相应数据记录。 MyISAM 的索引方式也叫做非聚集索引(稀疏索引)(索引和数据是分开存储的)。
InnoDB 索引存储机制
InnoDB 也使用 B+ 树作为索引结构。有且仅有一个聚集索引,和多个非聚集索引。
InnoDB 的数据文件本身就是索引文件。MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在 InnoDB 中,表数据文件本身就是按 B+ 树组织的一个索引结构,这棵树的叶子节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。
上图是 InnoDB 主索引(同时也是数据文件)的示意图。可以看到叶子节点包含了完整的数据记录。
这种索引叫做聚集索引(密集索引)(索引和数据保存在同一文件中):
- 若一个主键被定义,该主键作为聚集索引;
- 若没有主键定义,该表的第一个唯一非空索引作为聚集索引;
- 若均不满足,则会生成一个隐藏的主键( MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,这个字段是递增的,长度为 6 个字节)。
与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。例如,定义在 Col3 上的一个辅助索引:
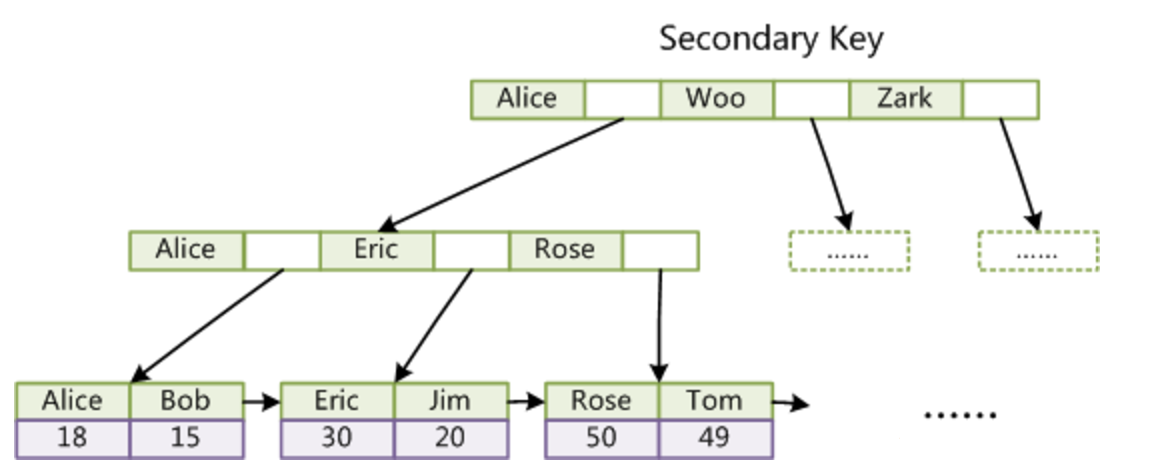
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索 2 遍索引:
首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
注意 InnoDB 索引机制中:
不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
不建议用非单调的字段作为主键,因为 InnoDB 数据文件本身是一棵 B+ 树,非单调的主键会造成在插入新记录时数据文件为了维持 B+ 树的特性而频繁的分裂调整,十分低效。
使用自增字段作为主键则是一个很好的选择。
索引的优点
- 大大减少了服务器需要扫描的数据行数。
- 帮助服务器避免进行排序和分组,以及避免创建临时表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。临时表主要是在排序和分组过程中创建,不需要排序和分组,也就不需要创建临时表)。
- 将随机 I/O 变为顺序 I/O(B+Tree 索引是有序的,会将相邻的数据都存储在一起)。
建索引的原则
最左前缀匹配原则
MySQL 会一直向右匹配知道遇到范围查询(>、<、between、like)就停止匹配。比如
a=3 and b=4 and c>5 and d=6,如果建立 (a,b,c,d) 顺序的索引,d 就是用不到索引的,如果建立(a,b,d,c) 的索引则都可以用到,并且 a,b,d 的顺序可以任意调整。= 和 in 可以乱序
比如
a = 1 and b = 2 and c = 3建立 (a,b,c) 索引可以任意顺序,MySQL 的查询优惠器可进行优化。尽量选择选择度高的列建索引
1
2
3
4
5# 选择度计算
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity,
COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity,
COUNT(*)
FROM payment;使用 like 进行模糊查询时,如果已经建立索引,第一个位置不要使用 ‘%’,否则索引会失效。
当检索性能远远大于检索性能时,不应该建立索引。
索引失效
最左前缀匹配原则,遇到范围查询
like 模糊查询,第一个位置使用 ‘%’
没有查询条件
表比较小时,全表扫描速度比索引速度快时,索引失效
(由于索引扫描后要利用索引中的指针去逐一访问记录,假设每个记录都使用索引访问,则读取磁盘的次数是查询包含的记录数T,而如果表扫描则读取磁盘的次数是存储记录的块数B,如果T>B 的话索引就没有优势了。)