前言 在Hibernate的第二篇中只是简单地说了Hibernate的几种查询方式….到目前为止,我们都是使用一些简单的主键查询阿…使用HQL查询所有的数据….本博文主要讲解Hibernate的查询操作,连接池,逆向工程的知识点 …
get/load主键查询 由于主键查询这个方法用得比较多,于是Hibernate专门为我们封装了起来…
对象导航查询 如果对象与对象之前存在一对多、多对一的关系的时候
在以前SQL查询的时候:我们如果想要得到当前对象与另一对象的关联关系的时候,就必须用多表查询来得到数据
Hibernate提供了对象导航查询:我们可以使用主键查询完之后,得到的对象,直接使用对象得到集合…就可以得到对应的数据了 。
1 2 3 4 5 6 Dept dept = (Dept) session.get(Dept.class, 12 );System.out.println(dept.getDeptName()); System.out.println(dept.getEmps());
HQL查询 在Hibernate的前面章节中已经讲解过了基本的概念了 。在这里我们就直接看看怎么使用了。
值得注意的是:
在hbm.xml文件中的auto-import=”true” 要设置true。当然了,默认值就是ture
如果是false,写hql的时候,要指定类的全名
查询全部列 1 2 3 4 5 6 Query q = session.createQuery("from Dept" );Query q = session.createQuery("select d from Dept d" );
值得注意的是:HQL不支持*号 ,下面的代码是错误的。
1 2 Query q = session.createQuery("select * from Dept d" );
查询指定的列 值得注意的是:使用HQL查询指定的列,返回的是对象数组Object[]
1 2 3 Query query = session.createQuery("select m.name,m.eatBanana from Monkey m" );System.out.println(query.list());
封装对象 前面测试了查询指定的列的时候,返回的是对象数组…可是对象数组我们不好操作啊…Hibernate还提供了将对象数组封装成对象的功能
1 Query query = session.createQuery("select new Monkey(m.name,m.eatBanana )from Monkey m" );
条件查询 在SQL中条件查询我们也用得比较多,我们来看看HQL中的条件查询有什么新特性。
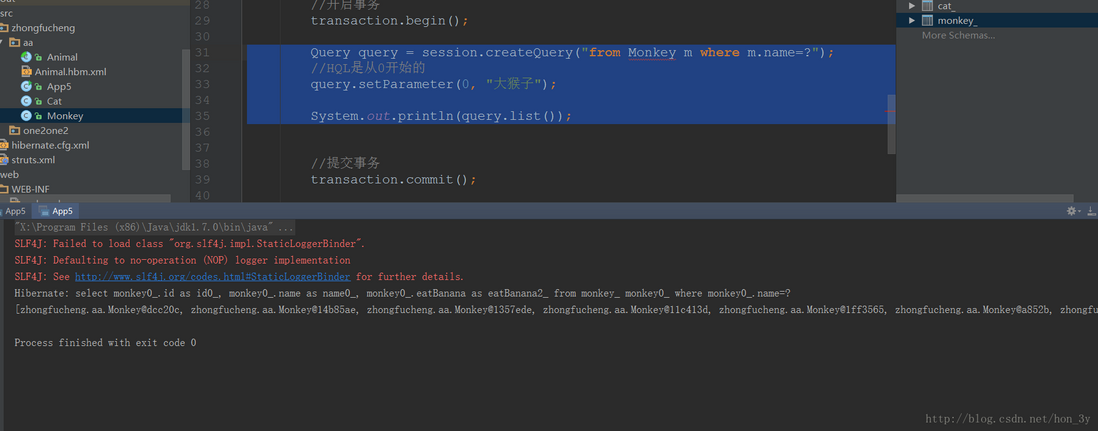
占位符 占位符就是指?号 ,我们在SQL中也常常用…
1 2 3 4 5 Query query = session.createQuery("from Monkey m where m.name=?" );query.setParameter(0 , "大猴子" ); System.out.println(query.list());
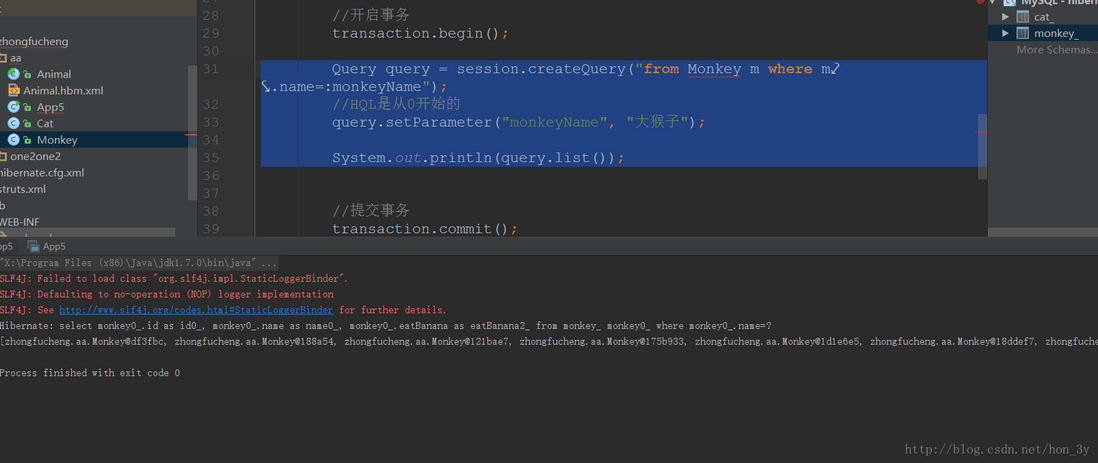
命名参数 HQL还支持命名参数查询 !下面我们来看一下怎么用:
语法::命名
1 2 3 4 Query query = session.createQuery("from Monkey m where m.name=:monkeyName" );query.setParameter("monkeyName" , "大猴子" ); System.out.println(query.list());
范围查询 范围查询就是使用between and关键字来查询特定范围的数据 。。和SQL是一样的…
1 2 3 4 Query q = session.createQuery("from Dept d where deptId between ? and ?" );q.setParameter(0 , 1 ); q.setParameter(1 , 20 ); System.out.println(q.list());
模糊查询 模糊查询就是使用Like关键字进行查询 ,和SQL也是一样的。
1 2 3 4 Query q = session.createQuery("from Dept d where deptName like ?" );q.setString(0 , "%部%" ); System.out.println(q.list());
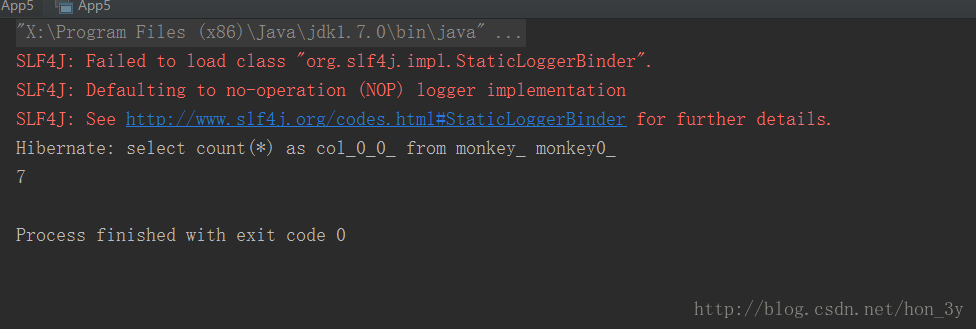
聚合函数统计 我们也经常会查询数据库中一共有多少条记录这样的需求。那么在HQL中怎么用呢?
HQL提供了uniqueResult()这么一个方法,返回只有一条记录的数据
1 2 3 Query query = session.createQuery("select COUNT(*) from Monkey" );Object o = query.uniqueResult();System.out.println(o);
分组查询 分组查询和SQL是一样的…
1 2 3 4 5 Query q = session.createQuery("select e.dept, count(*) from Employee e group by e.dept" );System.out.println(q.list());
连接查询 连接查询也就是多表查询…多表查询有三种
值得注意的是:连接查询返回的也是对象数组!
1 2 3 4 5 6 7 8 9 10 Query q = session.createQuery("from Dept d inner join d.emps" );Query q = session.createQuery("from Dept d left join d.emps" );Query q = session.createQuery("from Employee e right join e.dept" );q.list();
迫切连接 由于连接查询返回的是对象数组,我们使用对象数组来操作的话会很不方便…既然是连接查询,那么对象与对象是肯定有关联关系的 …于是乎,我们想把左表的数据填充到右表中,或者将右表的数据填充到左表中…使在返回的时候是一个对象、而不是对象数组! HQL提供了fetch关键字供我们做迫切连接 ~
1 2 3 4 5 6 7 Query q = session.createQuery("from Dept d inner join fetch d.emps" );q.list(); Query q = session.createQuery("from Dept d left join fetch d.emps" );q.list();
查询语句放在配置文件中【命名查询】 我们可以在具体的映射配置文件中存放一些常用的语句 。以Dept为例
1 2 3 4 5 6 <!-- 存放sql语句,如果有<>这样的字符数据,需要使用CDATA转义! --> <query name="getAllDept" > <![CDATA[ from Dept d where deptId < ? ]]> </query>
在程序中,我们可以获取配置文件配置的语句
1 2 3 Query q = session.getNamedQuery("getAllDept" );q.setParameter(0 , 10 ); System.out.println(q.list());
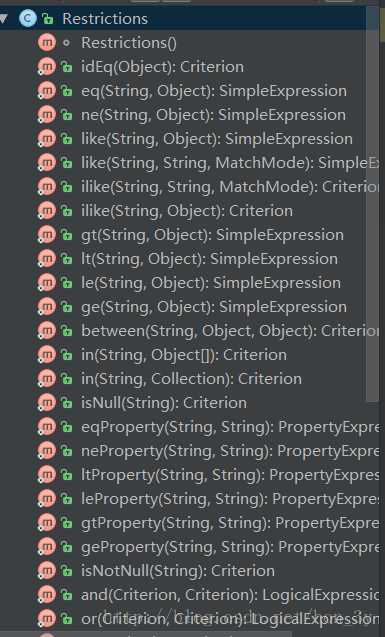
Criteria 查询 Criteria是一种完全面向对象的查询 …
Criteria使用的是add()来添加条件。条件又使用一个Restrictions类来封装
1 2 Criteria criteria = session.createCriteria(Monkey.class);criteria.add(Restrictions.eq())
我们来简单看一下Restrictions的方法:
都是一些大于、小于、等于之类的….Criteria查询就使用不了分组、连接查询了。
SQLQuery本地SQL查询 有的时候,我们可能表的结构十分复杂,如果使用关联映射的话,配置文件是十分臃肿的 …因此,我们并不是把全部的数据表都使用映射的方式来创建数据表…
这时,我们就需要用到SQLQuery来维护我们的数据了..
SQLQuery是不能跨数据库的,因为Hibernate在配置的时候就指定了数据库的“方言” …
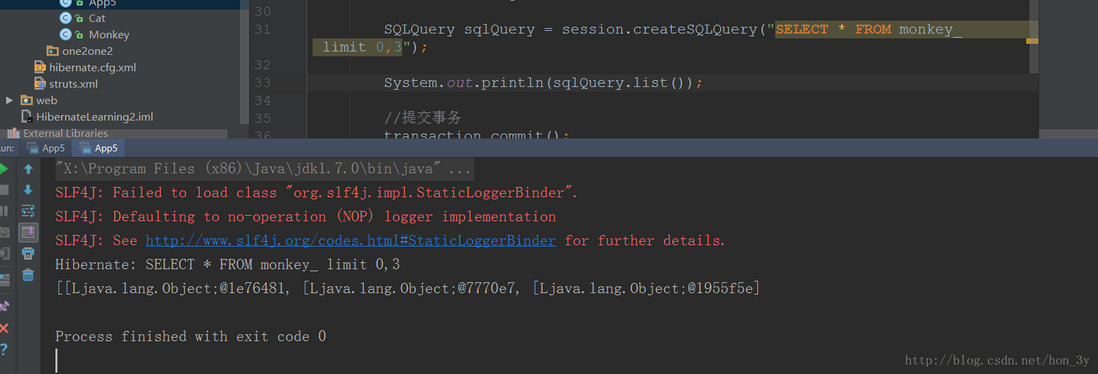
1 2 3 SQLQuery sqlQuery = session.createSQLQuery("SELECT * FROM monkey_ limit 0,3" );System.out.println(sqlQuery.list());
返回的也是对象数组:
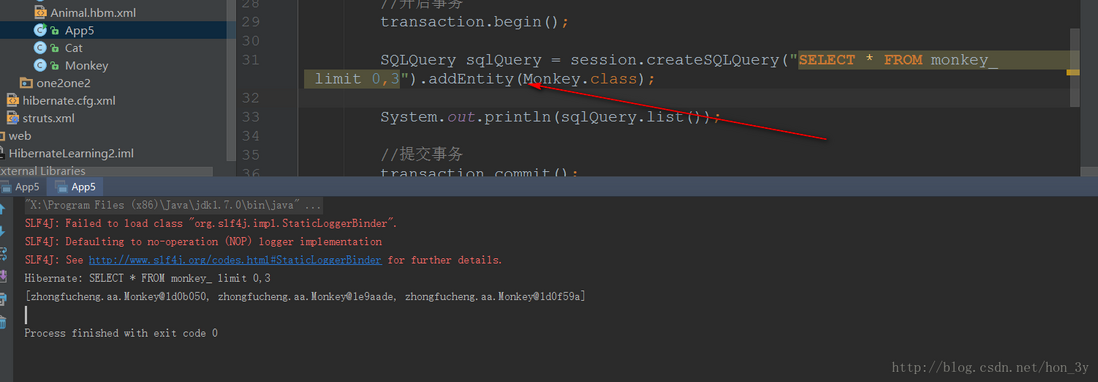
Hibernate也支持在SQLQuery中对数据进行对象封装..只要添加类型就行了
1 2 3 SQLQuery sqlQuery = session.createSQLQuery("SELECT * FROM monkey_ limit 0,3" ).addEntity(Monkey.class);System.out.println(sqlQuery.list());
分页查询 传统的SQL我们在DAO层中往往都是使用两个步骤来实现分页查询
得到数据库表中的总记录数 查询起始位置到末尾位数的数据
Hibernate对分页查询也有很好地支持,我们来一下:
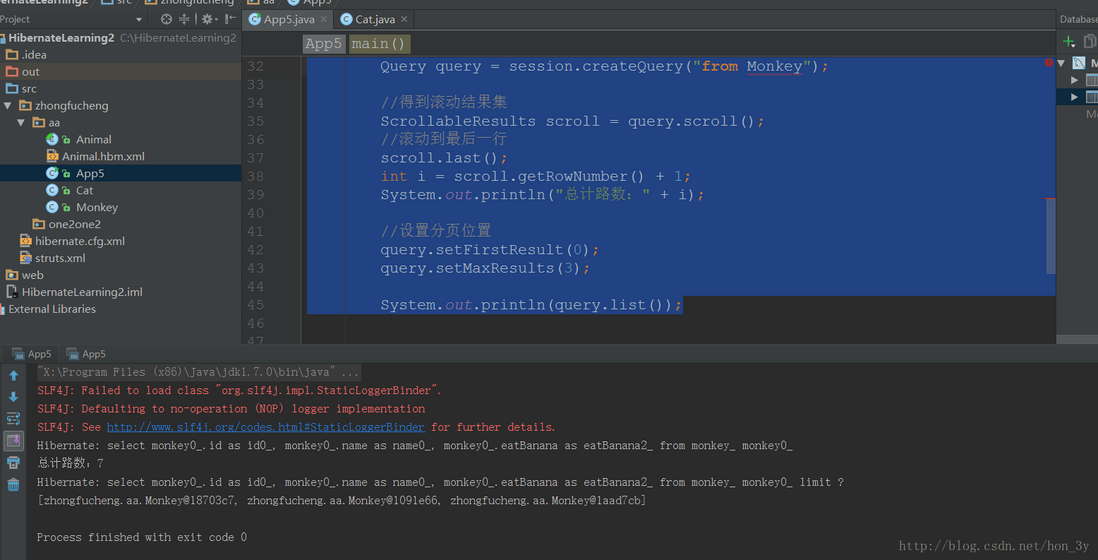
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Query query = session.createQuery("from Monkey" );ScrollableResults scroll = query.scroll();scroll.last(); int i = scroll.getRowNumber() + 1 ;System.out.println("总计路数:" + i); query.setFirstResult(0 ); query.setMaxResults(3 ); System.out.println(query.list());
提供了方法让我们设置起始位置和结束位置 提供了ScrollableResults来得到滚动结果集,最终得到总记录数
值得注意的是,滚动结果集是从0开始的,因此需要+1才可得到总记录数!
如果我们们使用的是SELECT COUNT(\*) FROM 实体,我们可以通过uniqueResult()方法获取数据的唯一记录,得到的数据转换成Long类型即可。
1 Long totalRecord = (Long) queryCount.uniqueResult();
Hibernate连接池 Hibernate自带了连接池,但是呢,该连接池比较简单..而Hibernate又对C3P0这个连接池支持…因此我们来更换Hibernate连接池为C3P0
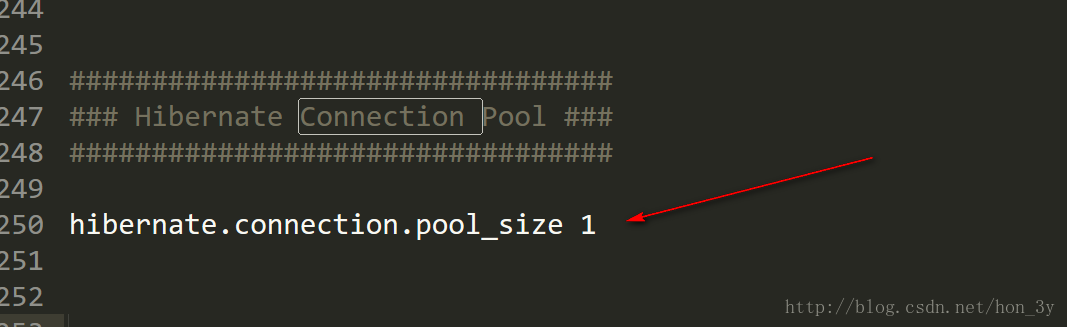
查看Hibernate自带的连接池 我们可以通过Hibernate.properties文件中查看Hibernate默认配置的连接池
hibernate.properties的配置文件可以在\project\etc找到
Hibernate的自带连接池啥都没有,就一个连接数量为1 …
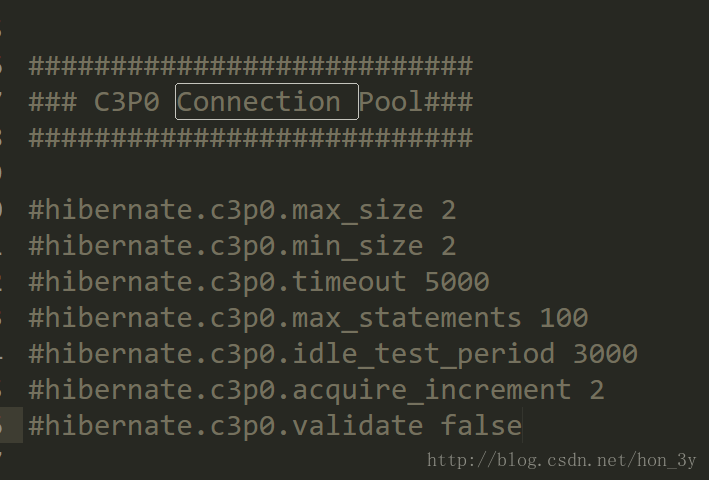
查看Hibernate对C3P0的支持
hibernate.c3p0.max_size 2 最大连接数
hibernate.c3p0.min_size 2 最小连接数
hibernate.c3p0.timeout 5000 超时时间
hibernate.c3p0.max_statements 100 最大执行的命令的个数
hibernate.c3p0.idle_test_period 3000 空闲测试时间
hibernate.c3p0.acquire_increment 2 连接不够用的时候, 每次增加的连接数
hibernate.c3p0.validate false
修改Hibernate连接池 我们在hibernate.cfg.xml中配置C3p0,让C30P0作为Hibernate的数据库连接池
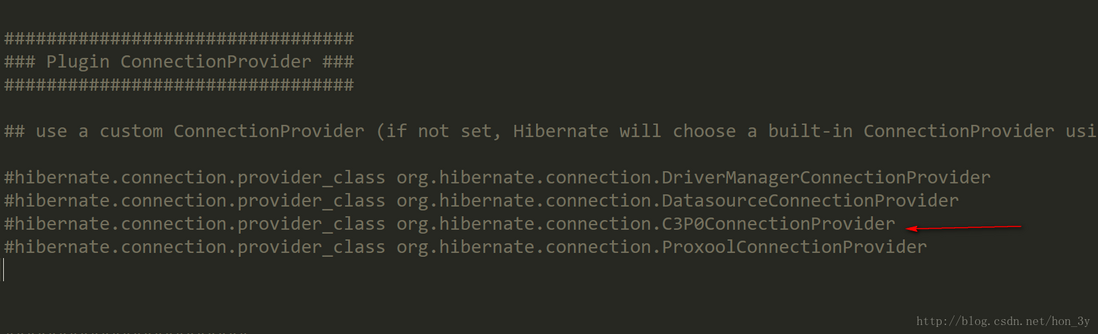
查找Hibernate支持的连接池组件有什么 :
既然找到了,那么我们在hibernate.cfg.xml中配置对应的类就和相关配置就行了
1 2 3 4 5 6 7 8 9 10 <property name ="hibernate.connection.provider_class" > org.hibernate.connection.C3P0ConnectionProvider</property > <property name ="hibernate.c3p0.min_size" > 2</property > <property name ="hibernate.c3p0.max_size" > 4</property > <property name ="hibernate.c3p0.timeout" > 5000</property > <property name ="hibernate.c3p0.max_statements" > 10</property > <property name ="hibernate.c3p0.idle_test_period" > 30000</property > <property name ="hibernate.c3p0.acquire_increment" > 2</property >
线程Session使用 我们创建Session的时候,有两个方法
openSession()【每次都会创建新的Session】 getCurrentSession()【获取当前线程的Session,如果没有则创建】
一般地,我们使用线程Session比较多
如果要使用getCurrentSession(),需要在配置文件中配置:
1 2 <property name ="hibernate.current_session_context_class" > thread</property >
测试数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Test public void testSession () throws Exception { Session session1 = sf.openSession(); Session session2 = sf.openSession(); System.out.println(session1 == session2); session1.close(); session2.close(); Session session3 = sf.getCurrentSession(); Session session4 = sf.getCurrentSession(); System.out.println(session3 == session4); }
为什么要使用逆向工程 由于我们每次编写Hibernate的时候都需要写实体,写映射文件。而且Hibernate的映射文件也容易出错。而逆向工程可以帮我们自动生成实体和映射文件,这样就非常方便了。
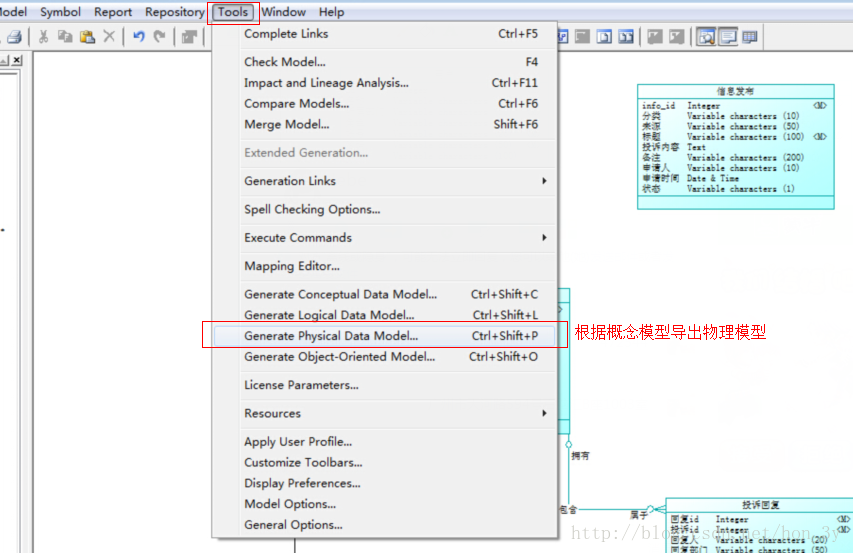
使用PowerDesigner 在设计数据库表时,我们使用PowerDesigner来生成概念模型物理模型…
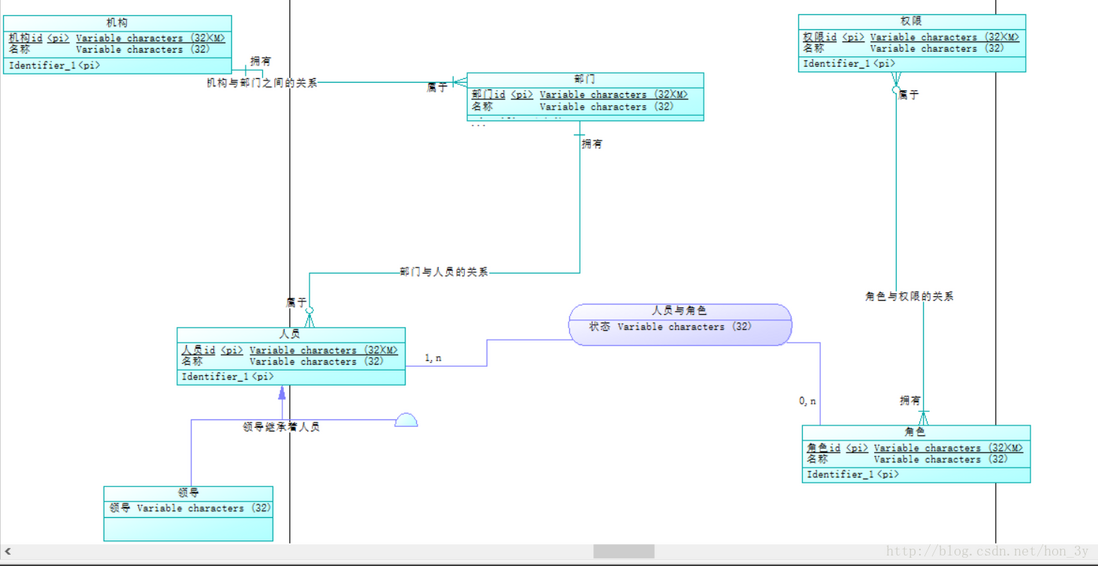
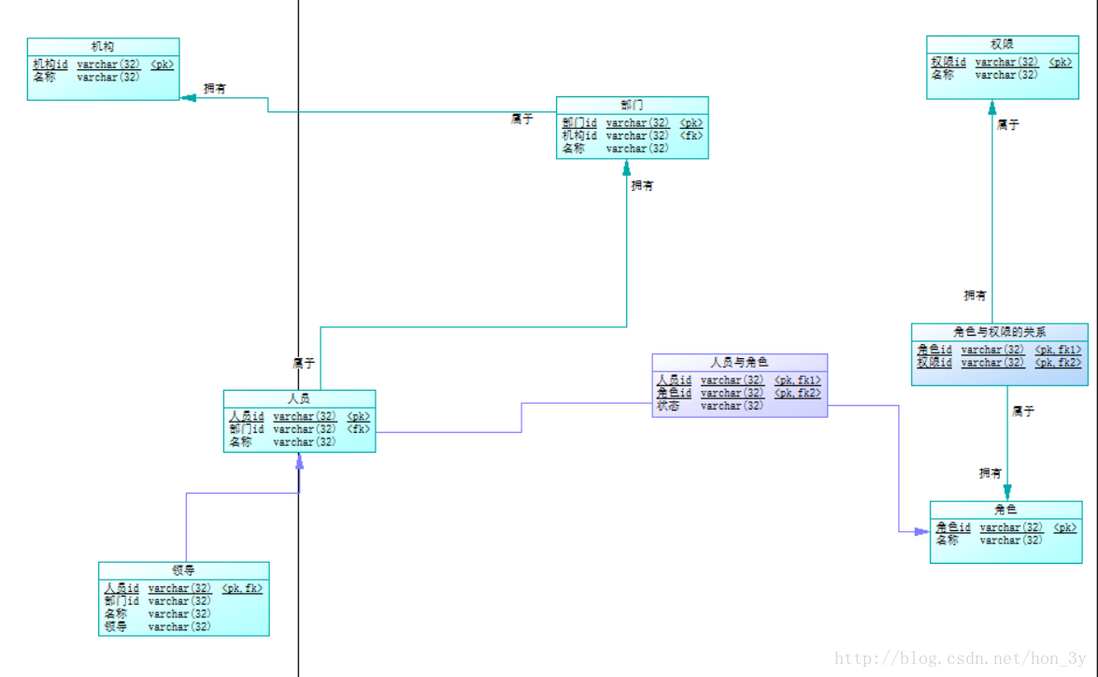
设计一个人员组织架构:有机构、部门、员工、领导、角色、权限。
一个机构有多个部门 一个部门有多个员工 领导可以管理多个部门,同时领导他自己也是员工 一个员工可以有多个角色 一个角色可以分配给多个人 人员角色分配后可以设置是否有效,分配时间等 一个角色有多个权限
概念模型:
在PowerDesigner中,箭头指向的方向永远是“一”的一方
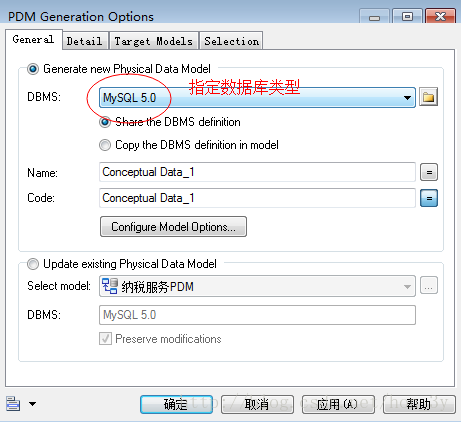
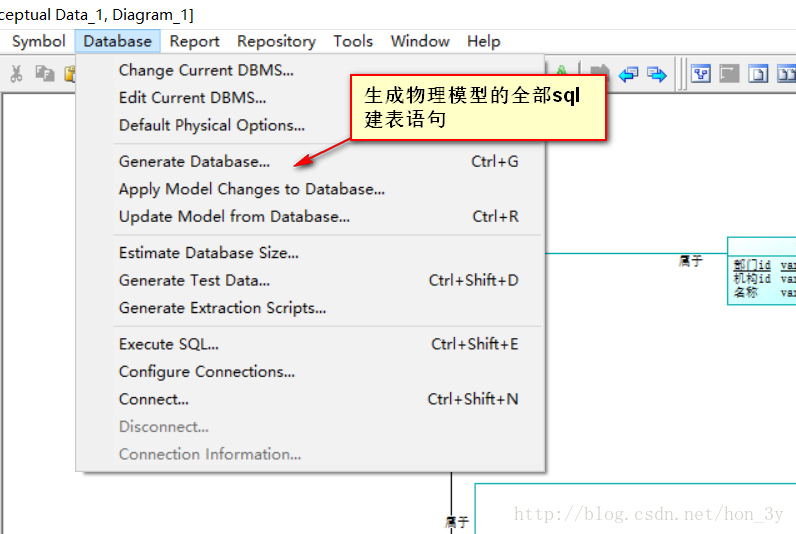
生成物理模型:
最后生成物理模型是这样子的:
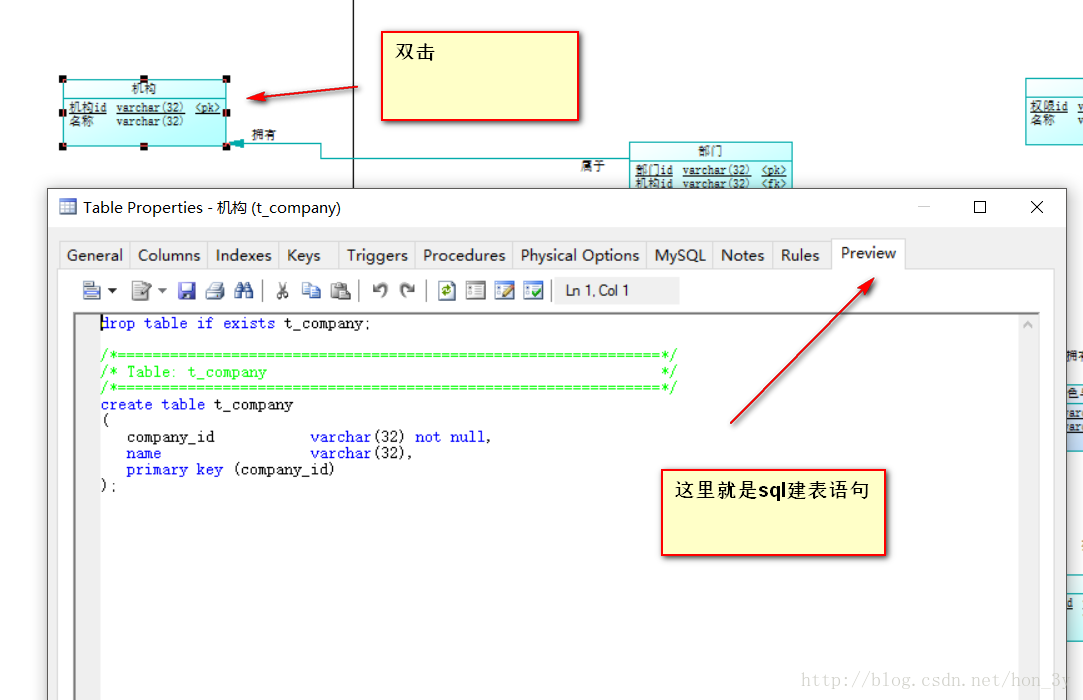
生成sql语句 我们可以单个生成,一个一个复制
也可以把整个物理模型的sql语句一起生成:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 drop table if exists person_role;drop table if exists t_company;drop table if exists t_dept;drop table if exists t_employee;drop table if exists t_person;drop table if exists t_privilege;drop table if exists t_role;drop table if exists t_role_privilege;create table person_role( person_id varchar (32 ) not null , role_id varchar (32 ) not null , state varchar (32 ), primary key (person_id, role_id) ); create table t_company( company_id varchar (32 ) not null , name varchar (32 ), primary key (company_id) ); create table t_dept( dept_id varchar (32 ) not null , company_id varchar (32 ) not null , name varchar (32 ), primary key (dept_id) ); create table t_employee( person_id varchar (32 ) not null , dept_id varchar (32 ), name varchar (32 ), employee_id varchar (32 ), primary key (person_id) ); create table t_person( person_id varchar (32 ) not null , dept_id varchar (32 ) not null , name varchar (32 ), primary key (person_id) ); create table t_privilege( privilege_id varchar (32 ) not null , name varchar (32 ), primary key (privilege_id) ); create table t_role( role_id varchar (32 ) not null , name varchar (32 ), primary key (role_id) ); create table t_role_privilege( role_id varchar (32 ) not null , privilege_id varchar (32 ) not null , primary key (role_id, privilege_id) ); alter table person_role add constraint FK_person_role foreign key (person_id) references t_person (person_id) on delete restrict on update restrict; alter table person_role add constraint FK_person_role2 foreign key (role_id) references t_role (role_id) on delete restrict on update restrict; alter table t_dept add constraint FK_companty_dept foreign key (company_id) references t_company (company_id) on delete restrict on update restrict; alter table t_employee add constraint FK_inherit foreign key (person_id) references t_person (person_id) on delete restrict on update restrict; alter table t_person add constraint FK_dept_person foreign key (dept_id) references t_dept (dept_id) on delete restrict on update restrict; alter table t_role_privilege add constraint FK_belong foreign key (role_id) references t_role (role_id) on delete restrict on update restrict; alter table t_role_privilege add constraint FK_own foreign key (privilege_id) references t_privilege (privilege_id) on delete restrict on update restrict;
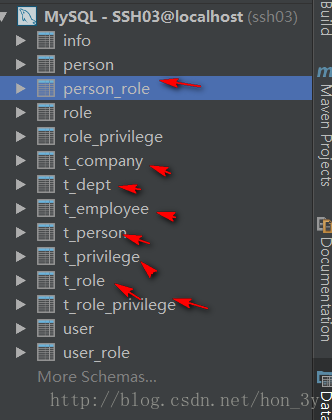
在数据库生成八张表:
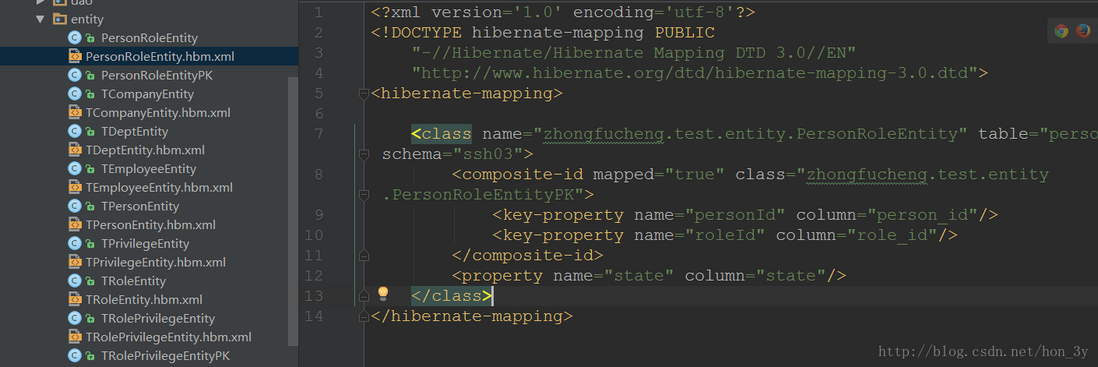
在Idea下使用Hibernate逆向工程
值得注意的是:Intellij idea下生成出来的映射文件是没有对应的关联关系的 。也就是说:一对多或多对多的关系,它是不会帮你自动生成的【好像是这样子的】 。。。因此,需要我们自己添加Set【如果需要】