Kafka
生产者发送消息的整体流程
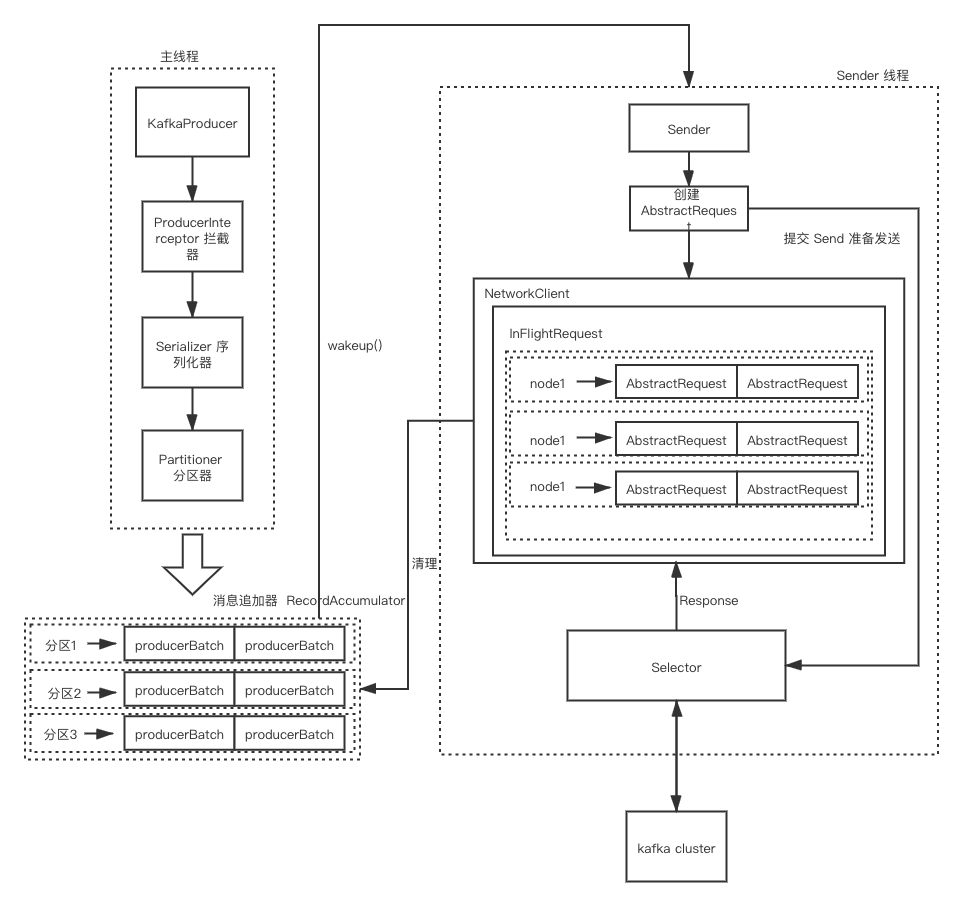
消息追加器 RecordAccumulator
前面几个组件,在 3.1 的文章中,已经说清楚。现在来看 RecordAccumulator 组件
RecordAccumulator 主要用于缓存消息,以便 Sender 线程能够批量发送消息。RecordAccumulator 会将消息放入缓存 BufferPool(实际上就是 ByteBuffer) 中。BufferPool 默认最大为 33554432B,即 32MB, 可通过 buffer.memory 进行配置。
当生产者生产消息的速度大于 sender 线程的发送速度,那么 send 方法就会阻塞。默认阻塞 60000ms,可通过 max.block.ms 配置。
RecordAccumulator 类的几个重要属性
1 | public final class RecordAccumulator { |
TopicPartition 为分区的抽象。定义如下所示
1 | public final class TopicPartition implements Serializable { |
主线程发送的消息,都会被放入batcher 中, batches 将发往不同 TopicPartition 的消息,存放到各自的 ArrayDeque<ProducerBatch> 中。
主线程 append 时,往队尾插入,sender 线程取出时,则往队头取出。
ProducerBatch 批量消息
ProducerBatch 为批量消息的抽象。
在编写客户端发送消息时,客户端面向的类则是 ProducerRecord,kafka 客户端,在发送消息时,会将 ProducerRecord 放入 ProducerBatch,使消息更加紧凑。
如果为每个消息都独自创建内存空间,那么内存空间的开辟和释放,则将会比较耗时。因此 ProducerBatch 内部有一个 ByteBufferOutputStream bufferStream(实则为 ByteBuffer), 使用 ByteBuffer 重复利用内存空间。
bufferStream 值的大小为:
1 | public final class RecordAccumulator { |
其中,batchSize 默认 16384B,即 16kb,可通过 batch.size 配置。第2个入参的值则为消息的大小。
需要注意的是,bufferStream 的内存空间是从 free 内存空间中划出的。
上面有说到,ProducerBatch 会使用 ByteBuffer 追加消息。但是,如果你看代码,你会发现 ProducerBatch 在做消息的追加时,会将消息放入 DataOutputStream appendStream。好像跟我们说的 不一样! 但是实际上,就是利用 ByteBuffer,这里还需要看 appendStream 是如何初始化的!
注:MemoryRecordsBuilder 为 ProducerBatch 中的一个属性
1 | public class MemoryRecordsBuilder { |
MemoryRecordsBuilder 初始化
1 | public class MemoryRecordsBuilder { |
可以看到实际上使用的还是 ByteBufferOutputStream bufferStream
Sender 线程
Sender 线程在发送消息时,会从 RecordAccumulator 中取出消息,并将放在 RecordAccumulator 中的 Deque<ProducerBatch> 转换成 Map<nodeId, List<ProducerBatch>>,这里的 nodeId 是 kafka 节点的 id。再发送给 kafka 之前,又会将消息封装成 Map<nodeId, ClientRequest>。
请求在从 Sender 发往 kafka 时,还会被存入 InFlightRequests
1 | public class NetworkClient implements KafkaClient { |
InFlightRequests
1 | /** |
InFlightRequests 的作用是存储已经发送的,或者发送了,但是未收到响应的请求。InFlightRequests 类中有一个属性 maxInFlightRequestsPerConnection, 标识一个节点最多可以缓存多少个请求。该默认值为 5, 可通过 max.in.flight.requests.per.connection 进行配置, 需要注意的是 InFlightRequests 对象是在创建 KafkaProducer 时就会被创建。
requests 参数的 key 为 nodeId,value 则为缓存的请求。
sender 线程 在发送消息时,会先判断 InFlightRequests 对应的请求缓存中是否超过了 maxInFlightRequestsPerConnection 的大小
代码入口:Sender.sendProducerData
1 | public class Sender implements Runnable { |
从 InFlightRequests 的设计中,可以看到,我们可以很轻松的就知道,哪个 kafka 节点的负载是最低。因为只需要判断 requests 中对应 node 集合的大小即可。
重要参数
acks
用于指定分区中需要有多少个副本收到消息,生产者才会认为消息是被写入的acks= 1。默认为1, 只要leader副本写入,则被认为已经写入。如果消息已经被写入leader副本,且已经返回给生产者ok,但是在follower拉取leader消息之前,leader副本突然挂掉,那么此时消息也会丢失acks= 0。发送消息后,不需要等待服务端的响应,此配置,吞吐量最高。acks= -1 或者 all。需要等待所有ISR中的所有副本都成功写入消息之后,才会收到服务端的成功响应。
需要注意的一点是acks入参是String,而不是intmax.request.size
客户端允许发送的消息最大长度,默认为1MB.retries、retry.backoff.msretries配置生产者的重试次数,默认为0.retry.backoff.ms配置两次重试的间隔时间compression.type
指定消息的压缩方式,默认为 **none**。可选配置gzip,snappy,lz4connection.max.idle.ms
指定在多久之后关闭闲置的连接,默认540000(ms),即9分钟linger.ms
指定发送ProducerBatch之前等待更多的消息(ProducerRecord) 加入ProducerBatch的时间,默认为0。生产者在ProducerBatch填充满时,或者等待时间超过linger.ms发送消息出去。receive.buffer.bytes
设置Socket接收消息缓存区的大小,默认32678B,32KB。如果设置为-1, 则表示使用 操作系统的默认值。如果Procuer和kafka处于不同的机房,可以调大此参数。send.buffer.bytes
设置Socket发送消息缓冲区大小。默认131072B, 即128KB。如果设置为-1,则使用操作系统的默认值request.timeout.msProducer等待响应的最长时间,默认30000ms。需要注意的是,该参数需要比replica.lag.time.max.ms值更大。可以减少因客户端重试,而造成的消息重复buffer.memory
配置消息追加器,内存大小。默认最大为33554432B,即32MBbatch.sizeProducerBatchByteBuffer。默认16384B,即16kbmax.block.ms
生产者生成消息过快时,客户端最多阻塞多少时间。
总结
kafka将生产者生产消息,消息发送给服务端,拆成了 2 个过程。生产消息交由 主线程, 消息发送给服务端的任务交由sender线程。- 通过
RecordAccumulator的设计,将生产消息,与发送消息解耦。 RecordAccumulator内部存储数据的数据结构是ArrayDeque. 队尾追加消息,队头取出消息- 开发人员编写的
ProducerRecord,在消息发送之前会被转为ProducetBatch。为的是批量发送消息,提高网络 IO 效率 - 为了避免,每个节点负载过高,
kafka设计了InFlightRequests, 将为响应的消息放入其中 - 从源码角度,
batch.size最好是buffer.memory整数倍大小。因为ProducerBatch的ByteBuffer是从RecordAccumulator的ByteBuffer中划出的
与 RocketMQ 区别
RocketMQ没有将生产消息与发送消息解耦。RocketMQ的消息发送,分为 同步,异步、单向。其中单向发送与kafka的acks= 0 的配置效果一样。但是实际上,还得看RocketMQ broker的刷盘配置!kafka发送失败,默认不重试,RocketMQ默认重试 2 次。不过RocketMQ无法配置 2 次重试的间隔时间.kafka可以配置重试的间隔时间。RocketMQ默认消息最大为4MB,kafka默认1MBRocketMQ在消息的发送上,是直接使用Netty。kafka则是使用NIO自己实现通信。(虽说,Netty也是基于NIO)- 当然还有很多咯….., 因为设计完全不一样!,实际解决场景也不一样
知识补充
ByteBuffer
ByteBuffer 一般用于网络传输的缓冲区。
先来看下 ByteBuffer 的类继承体系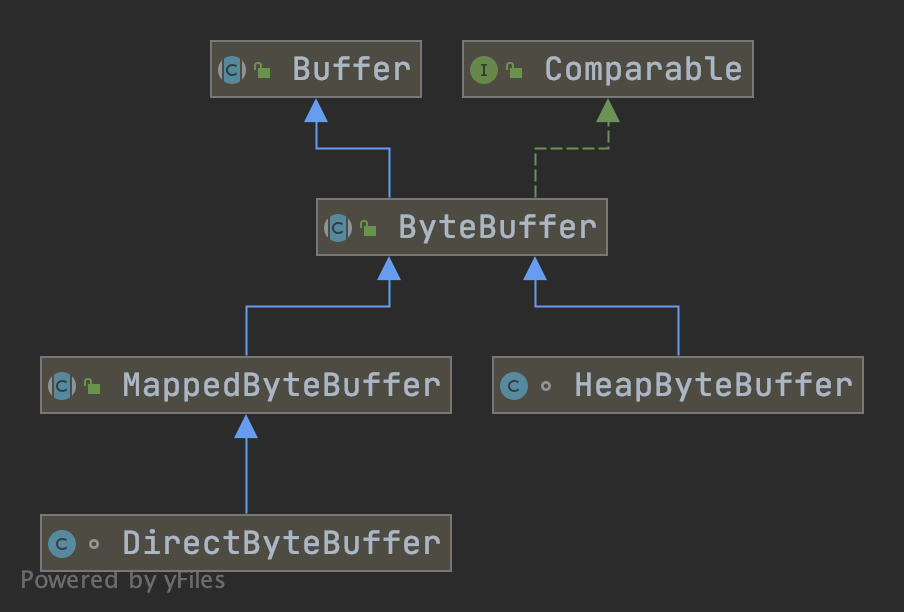
ByteBuffer 主要的 2 个父类。 DirectByteBuffer、HeapByteBuffer。一般而言,我们主要的是使用 HeapByteBuffer。
ByteBuffer 重要属性
position
当前读取的位置mark
为某一读过的位置做标记,便于某些时候回退到该位置limit
读取的结束位置capacitybuffer大小
ByteBuffer 基本方法
put()
往buffer中写数据,并将position往前移动flip()
将position设置为0,limit设置为当前位置rewind()
将position设置为0,limit不变mark()
将mark设置为当前position值,调用reset(), 会将mark赋值给positionclear()
将position设置为0,limit设置为capacity
ByteBuffer 食用DEMO
1 | FileInputStream fis = new FileInputStream("/Users/chenshaoping/text.txt"); |
ArrayDeque
ArrayDeque,是一个双端队列。即可以从队头插入元素,也可以从队尾插入元素
对于双端队列,既可以使用 链表的方式实现,也可以使用数组的方式实现。JDK 中 LinkedList 使用链表实现,ArrayDeque 则使用数组的方式实现
来看 ArrayDeque 的实现。
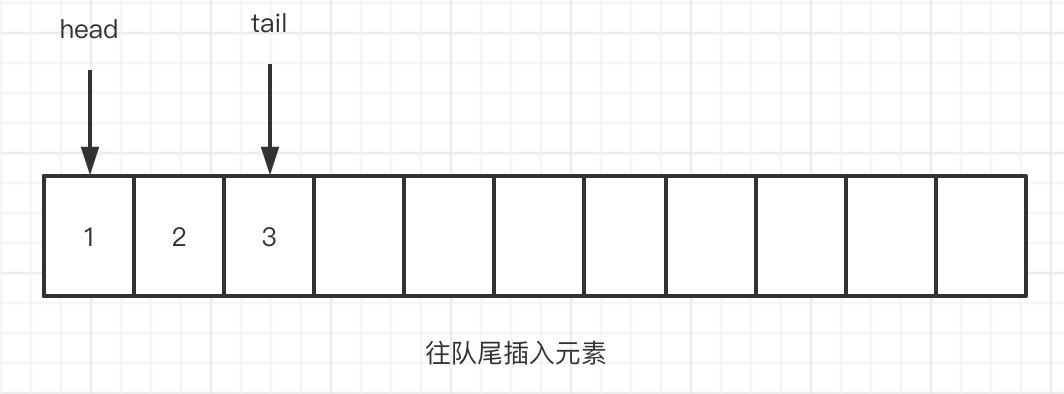
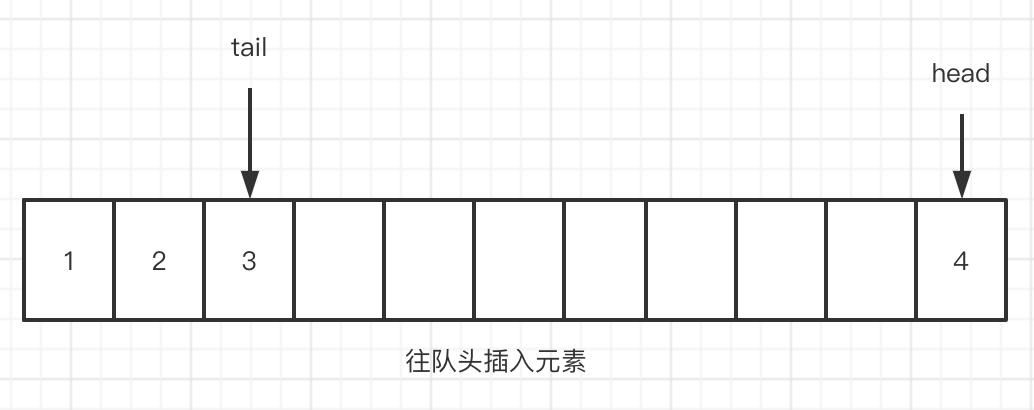
ArrayDeque 中,有 head, tail 分别指向 头指针,和尾指针。可以把 ArrayDeque 想象成循环数组
插入
- 当往队尾插入元素时,tail 指针会往前走
- 当往队前插入元素时, head 指针会向后走
删除
- 从队头删除元素 4 ,
head会往前走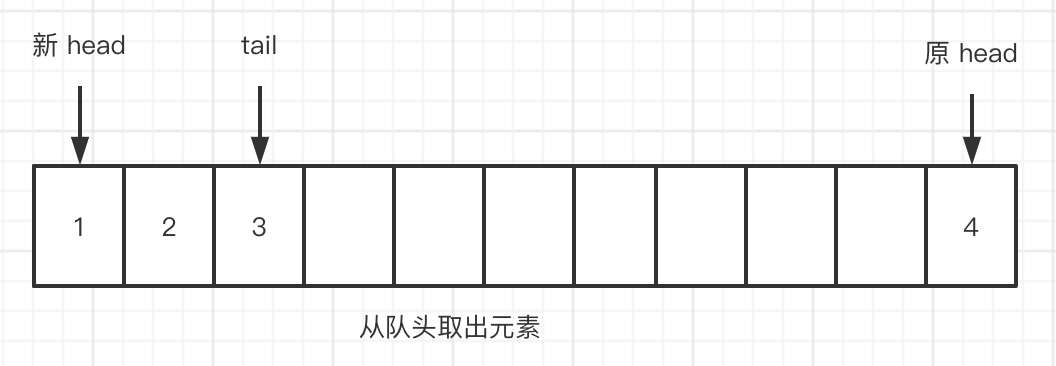
- 从队尾删除元素 3,
tail会往后走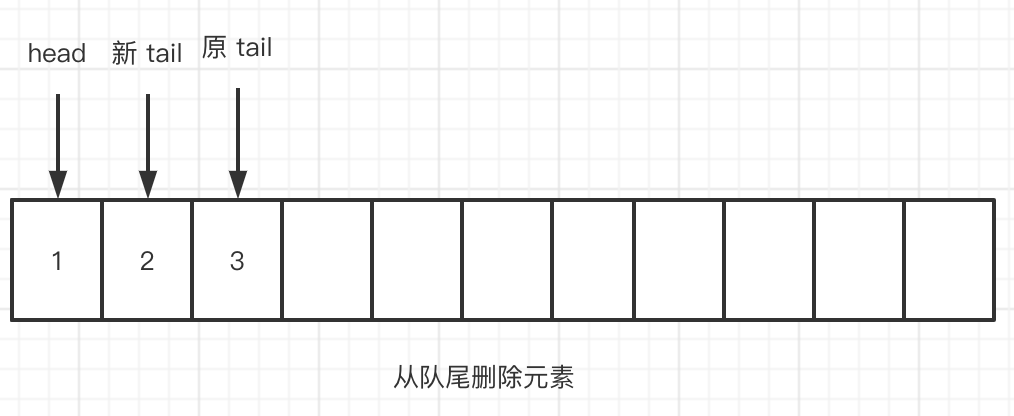
可以看到,这里通过移动 head, tail 指针就可以删除元素了。
扩容
当 tail、head 都指向都一个位置时,则需要扩容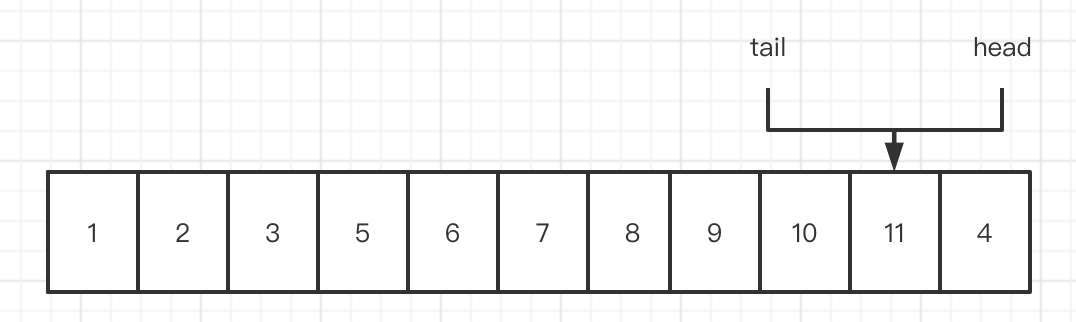
扩容会将数组的大小扩充为原来的 2 倍,然后重新将 head 指向数组 0 下标, tail 指向数组的最后一个元素位置。
上面的数组,在重新扩容后,会变成下面这个样子
1 | public class ArrayDeque<E> extends AbstractCollection<E> |