Kafka 消费者基本介绍
1、消费者食用DEMO
1 | Properties prop = new Properties(); |
2、消费者基本概念
kafka 消费者是以 组为基本单位 进行消费的。消费的模型如下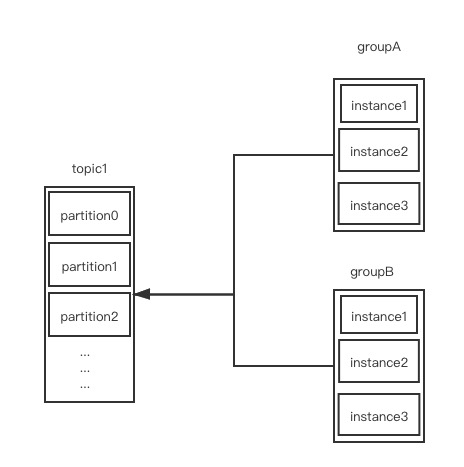
1 个 topic 允许被多个 消费组 消费。再次强调,kafka 消费是以组为单位。
1 | prop.put(ConsumerConfig.GROUP_ID_CONFIG, "testConsumer"); |
以上这行代码设置了消费组。
2.1、partition 分配
topic 为逻辑上的概念,partition 才是物理上的概念。那么看完这个以上的消费模型图。你可能会很疑惑。当一个组下有多个消费者时,每个消费者是如何消费的?
先说明:partition 的分配为平均分配
假设一:topic1 下面有 3 个分区。分别如下:p1 - p3。那么 groupA 下的三个消费者消费的对应 partition 为如下
1 | instance1: p1 |
假设二:topic1 下面有 8 个分区。分别为 p1 - p8。那么 groupA 中每个消费者分配到的 partition 就如下
1 | instance1: p1,p2,p3 |
2.2、partition 重分配
假设三:topic1 下面有 8 个分区:P1 - P8。groupA 有三个消费者:c1,c2,c3。此时分配的 partition 如下
1 | c1: p1,p2,p3 |
如果此时,又有一个新的消费者加入到 groupA 会发生什么呢? partition 会被重新分配
1 | c1: p1,p2 |
3、消费者端 API 介绍
3.1、订阅主题
1 | void subscribe(Collection<String> topics); |
从方法上看 kafka 允许一个消费者订阅多个 topic。
1 | void subscribe(Pattern pattern); |
入参 Pattern 则表示,可以使用正则表达式匹配多个 topic. 实例代码如下
1 | Pattern pattern = Pattern.compile("test?"); |
可以订阅主题,那么自然也可以取消订阅主题
1 | consumer.unsubscribe(); |
当然,也可以直接获取到消费组订阅的主题
1 | Set<String> topics = consumer.subscription(); |
一个主题下面有多个 partition, 那么是否可以指定要消费的队列呢?答案是可以的
1 | TopicPartition p1 = new TopicPartition("test1", 0); |
不过需要注意的是,如果指定了消费的分区,那么是消费者是无法自动 rebanlance 的。
3.2、消息消费
1 | ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); |
从消费者端的这行代码,我们可以看出,kafka 消息消费采用的是拉取模式。当未拉取到消息时,会阻塞线程。
poll 方法返回的 ConsumerRecords 实现 Iterable 接口,是 ConsumerRecord 的迭代器。ConsumerRecord 属性相对简单
1 | public class ConsumerRecord<K, V> { |
3.3、位移提交
对于分区而言,消息会有一个唯一 offset, 表示消息在分区中的位置,称之为 偏移量。对于消息消费而言,也有消费进度的 offset,称之为 位移。kafka 将消息的消费进度存储在 kafka 内部主题 __onsumer_offset 中。kafka 中默认每隔 5s 保存消息的消费进度。可通过 auto.commit.interval.ms 进行配置。
kafka 提供手动提交的 API,下面演示一下。
1 | Properties prop = new Properties(); |
需要注意的是,需要将 enable.auto.commit 设置为 true.
3.4、设置新消费组从哪个位置开始消费
kafka 设置 新消费组 从哪个位置开始消费的配置为:auto.offset.reset
该配置有以下 3 个配置项
latest(默认配置)
默认从最新的位置,开始消费。
earliest
从最早的位置开始消费。当配置为该参数时,kafka 会打印如下日志:Resetting offset for partition
none
当消费组,没有对应消费进度时,会直接抛 NoOffsetForPartitionException 异常
kafka 还提供了 seek(TopicPartition partition, long offset) 方法,允许新的消费者,设置从哪个位置开始消费。
1 | // 因为分配 分区的动作,发生在 pool 中,因此在设置消费偏移量时,需要先拉取消息 |
更多情况下,我们可能会指定消费组从指定的时间点开始消费
1 | Map<TopicPartition, Long> timestampToSearch = new HashMap<>(); |
3.5、分区再均衡
在分区再均衡期间,消费组内的消费者是无法读取消息的。并且如果之前的消费者没有及时提交消费进度,那么会造成重复消费。
kafka 在 subscribe 的时候,提供了回调函数,允许我们在触发再均衡时,做控制
1 | void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) |
看一下 ConsumerRebalanceListener 定义的接口
1 | // 再均衡开始之前和消费者停止读取消息之前被调用,可利用该会掉,提交消费位移 |
下面演示,如何在再均衡之前,提交消费偏移
1 | consumer.subscribe(Collections.singleton("test"), new ConsumerRebalanceListener() { |
3.6、消费者拦截器
消费者,允许在 消费之前,消费偏移提交之后,关闭之前,进行控制,多个拦截器则组成拦截器链, 且多个拦截器之前需要用 ‘,’ 号隔开。
先看拦截器定义的接口
1 | public interface ConsumerInterceptor<K, V> extends Configurable { |
3.7、重要的消费者参数
fetch.min.bytes
默认 1B,poll 时,拉取的最小数据量。
fetch.max.bytes
默认 5242880B,50MB,poll 时,拉取的最大数据量。
fetch.max.wait.ms
默认 500ms,如果 kafka 一直没有触发 poll 动作,那么最多等待 fetch.max.wait.ms。
max.partition.fetch.bytes
默认 1048576B,1MB,分区拉取时的最大数据量
max.poll.records
默认 500条,拉取的最大消息条数
connections.max.idle.ms
默认 540000ms, 9分钟,多久关闭闲置的连接
receive.buffer.bytes
默认 65536B,64KB,SOCKET 接受消息的缓冲区(SO_RECBUF)
request.timeout.ms
默认 30000ms,配置 consumer 等待请求响应的最长时间
metadata.max.age.ms
默认 300000ms,5 分钟,配置元数据过期时间。元数据在限定的时间内,没有更新,会被强制更新
reconnect.backoff.ms
默认 50ms,配置尝试连接指定主机之前的等待时间,避免频繁连接主机
retry.backoff.ms
默认 100ms,发送失败时,2次的间隔时间
4、总结
kafka消费以组为单位,且允许一个消费组订阅多个topicpartition重分配算法,为平均算法KafkaConsumer为线程不安全。因此poll()只有当前线程在拉取消息。kafka要实现多线程拉取相对麻烦kafka消费者端,提供的API非常灵活,允许从指定的位置消费,允许手动提交某个分区的消费偏移kafka提供消费者拦截器链,允许在 消费之前,提交消费偏移之后 控制。
5、与 RocketMQ 异同
RocketMQ建议 1 个消费组只消费一个topic, 且在实际开发中,如果消费者订阅多个topic会无法正常工作。kafka中 1 个消费者可以订阅多个topic。RocketMQ可以确保消费时,消息不丢失,kafka无法保证。RocketMQ在消费者端,实现了多线程消费,kafka则没有kafka默认每5s持久化消费进度,RocketMQ也是。不过RocketMQ会提交偏移量最小的消息。比如,线程 A 消费了 20 的消息。线程 B 消费了 10 的消息。当线程 A 提交消费进度的时候,会提交 10,而不会提交20。这也是RocketMQ可以确保消息消费时不丢的原因。RocketMQ发生rebalance,即kafka的再分配。默认和kafka一致,采用的是平均分配算法。不过RocketMQ允许自定义再分配算法,且提供了丰富算法支持。RocketMQ与kafka一致,都存在重复消费问题。- 从暴露出来的
API来看,kafka客户端会比RocketMQ更加灵活。 kafka设置 新的消费组 从哪个位置开始消费,没有额外的条件限制;RocketMQ只有当旧消息堆积非常多时,才会有效。