AT模式的核心点:
获取全局锁、开启全局事务
解析SQL并写入undolog
分析AT模式如何解析SQL并写入undolog,首先我们要先明确实际上Seata其中采用了数据源代理的模式。
那么这个就需要我们在回顾一下GlobalTransactionScanner这个类型,在这个类型中继承了一些的接口和抽象类,比较关键的几个:
AbstractAutoProxyCreator
InitializingBean
ApplicationContextAware
DisposableBean
这里给大家回顾一下:
继承ApplicationContextAware类型以后,需要实现对应的方法:
void setApplicationContext(ApplicationContext applicationContext) throws BeansException
当spring启动完成后,会自动调用这个类型,把ApplicationContext给bean。也就是说,GlobalTransactionScanner天然能拿到Spring的环境。
继承了InitializingBean接口,需要实现一个方法:
void afterPropertiesSet() throws Exception;
凡是继承该接口的类,在初始化bean的时候,当所有properties都设置完成后,会执行该方法。
继承DisposableBean,需要实现一个方法:
void destroy() throws Exception;
和InitializingBean接口相反,这个是在销毁的时候会调用这个方法。
AbstractAutoProxyCreator就比较复杂了,它Spring实现AOP的一种方式。本质上是一个BeanPostProcessor,他在bean初始化之前,调用内部的createProxy方法,创建一个bean的AOP代理bean并返回,对Bean的增强。
总结一下:总体的逻辑就是,GlobalTransactionScanner扫描有注解的bean,做AOP增强。
数据源代理 关于数据源代理这里我们
全局事务拦截成功后最终还是执行了业务方法的,但是由于Seata对数据源做了代理,所以sql解析与undolog入库操作是在数据源代理中执行的,箭头处的代理就是Seata对DataSource,Connection,Statement做的代理封装类
数据源代理是非常重要的一个环节。我们知道,在分布式事务运行过程中,undo log等的记录、资源的锁定等,都是用户无感知的,因为这些操作都在数据源的代理中完成了。
数据源代理DataSourceProxy DataSourceProxy的主要功能为,它在构造方法中调用了一个自定义的init方法,主要做了以下能力的增强:
为每个数据源标识了资源组ID
如果配置打开,会有一个定时线程池定时更新表的元数据信息并缓存到本地
生成代理连接ConnectionProxy
那我们先来看init方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 private void init (DataSource dataSource, String resourceGroupId) { this .resourceGroupId = resourceGroupId; try (Connection connection = dataSource.getConnection()) { jdbcUrl = connection.getMetaData().getURL(); dbType = JdbcUtils.getDbType(jdbcUrl); if (JdbcConstants.ORACLE.equals(dbType)) { userName = connection.getMetaData().getUserName(); } } catch (SQLException e) { throw new IllegalStateException ("can not init dataSource" , e); } DefaultResourceManager.get().registerResource(this ); if (ENABLE_TABLE_META_CHECKER_ENABLE) { tableMetaExcutor.scheduleAtFixedRate(() -> { try (Connection connection = dataSource.getConnection()) { TableMetaCacheFactory.getTableMetaCache(DataSourceProxy.this .getDbType()) .refresh(connection, DataSourceProxy.this .getResourceId()); } catch (Exception ignore) { } }, 0 , TABLE_META_CHECKER_INTERVAL, TimeUnit.MILLISECONDS); } RootContext.setDefaultBranchType(this .getBranchType()); }
这3个增强里面,前两个都比较容易理解,第三是最重要的。我们知道在AT模式里面,会自动记录undo log、资源锁定等等,都是通过ConnectionProxy完成的。
另外,DataSourceProxy重写了几个方法。
重点是getConnection,此时会返回一个ConnectionProxy,而不是原生的Connection
1 2 3 4 5 6 7 8 9 10 11 @Override public ConnectionProxy getConnection () throws SQLException { Connection targetConnection = targetDataSource.getConnection(); return new ConnectionProxy (this , targetConnection); } @Override public ConnectionProxy getConnection (String username, String password) throws SQLException { Connection targetConnection = targetDataSource.getConnection(username, password); return new ConnectionProxy (this , targetConnection); }
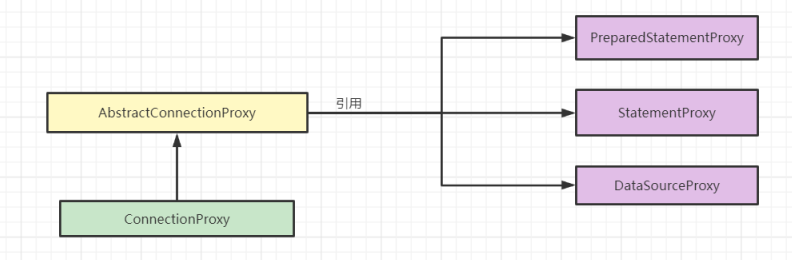
ConnectionProxy分析 ConnectionProxy继承了AbstractConnectionProxy。一看到Abstract,就知道它的父类封装了很多通用工作。它的父类里面还使用了PreparedStatementProxy、StatementProxy、DataSourceProxy。
我们先来分析AbstractConnectionProxy
AbstractConnectionProxy 在这个抽象连接对象中,定义了很多通用的逻辑,所以在这其中我们要关注的主要在于PreparedStatementProxy和StatementProxy,其实这里的通用逻辑就是数据源连接的步骤,获取连接,创建执行对象等等这些
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 @Override public Statement createStatement () throws SQLException { Statement targetStatement = getTargetConnection().createStatement(); return new StatementProxy (this , targetStatement); } @Override public PreparedStatement prepareStatement (String sql) throws SQLException { String dbType = getDbType(); PreparedStatement targetPreparedStatement = null ; if (BranchType.AT == RootContext.getBranchType()) { List<SQLRecognizer> sqlRecognizers = SQLVisitorFactory.get(sql, dbType); if (sqlRecognizers != null && sqlRecognizers.size() == 1 ) { SQLRecognizer sqlRecognizer = sqlRecognizers.get(0 ); if (sqlRecognizer != null && sqlRecognizer.getSQLType() == SQLType.INSERT) { TableMeta tableMeta = TableMetaCacheFactory.getTableMetaCache(dbType).getTableMeta(getTargetConnection(), sqlRecognizer.getTableName(), getDataSourceProxy().getResourceId()); String[] pkNameArray = new String [tableMeta.getPrimaryKeyOnlyName().size()]; tableMeta.getPrimaryKeyOnlyName().toArray(pkNameArray); targetPreparedStatement = getTargetConnection().prepareStatement(sql,pkNameArray); } } } if (targetPreparedStatement == null ) { targetPreparedStatement = getTargetConnection().prepareStatement(sql); } return new PreparedStatementProxy (this , targetPreparedStatement, sql); }
分布式事务SQL执行 在这两个代理对象中,执行SQL语句的关键方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Override public ResultSet executeQuery (String sql) throws SQLException { this .targetSQL = sql; return ExecuteTemplate.execute(this , (statement, args) -> statement.executeQuery((String) args[0 ]), sql); } @Override public int executeUpdate (String sql) throws SQLException { this .targetSQL = sql; return ExecuteTemplate.execute(this , (statement, args) -> statement.executeUpdate((String) args[0 ]), sql); } @Override public boolean execute (String sql) throws SQLException { this .targetSQL = sql; return ExecuteTemplate.execute(this , (statement, args) -> statement.execute((String) args[0 ]), sql); }
其他执行SQL语句的方法与上面三个方法都是类似的,都是调用ExecuteTemplate.execute方法,下面来看一下ExecuteTemplate类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 /** * The type Execute template. * * @author sharajava */ public class ExecuteTemplate { /** * Execute t. * * @param <T> the type parameter * @param <S> the type parameter * @param statementProxy the statement proxy * @param statementCallback the statement callback * @param args the args * @return the t * @throws SQLException the sql exception */ public static <T, S extends Statement> T execute(StatementProxy<S> statementProxy, StatementCallback<T, S> statementCallback, Object... args) throws SQLException { return execute(null, statementProxy, statementCallback, args); } /** * Execute t. * * @param <T> the type parameter * @param <S> the type parameter * @param sqlRecognizers the sql recognizer list * @param statementProxy the statement proxy * @param statementCallback the statement callback * @param args the args * @return the t * @throws SQLException the sql exception */ public static <T, S extends Statement> T execute(List<SQLRecognizer> sqlRecognizers, StatementProxy<S> statementProxy, StatementCallback<T, S> statementCallback, Object... args) throws SQLException { // 如果没有全局锁,并且不是AT模式,直接执行SQL if (!RootContext.requireGlobalLock() && BranchType.AT != RootContext.getBranchType()) { // Just work as original statement return statementCallback.execute(statementProxy.getTargetStatement(), args); } // 得到数据库类型 ->MySQL String dbType = statementProxy.getConnectionProxy().getDbType(); if (CollectionUtils.isEmpty(sqlRecognizers)) { //sqlRecognizers为SQL语句的解析器,获取执行的SQL,通过它可以获得SQL语句表名、相关的列名、类型的等信息,最后解析出对应的SQL表达式 sqlRecognizers = SQLVisitorFactory.get( statementProxy.getTargetSQL(), dbType); } Executor<T> executor; if (CollectionUtils.isEmpty(sqlRecognizers)) { //如果seata没有找到合适的SQL语句解析器,那么便创建简单执行器PlainExecutor, //PlainExecutor直接使用原生的Statement对象执行SQL executor = new PlainExecutor<>(statementProxy, statementCallback); } else { if (sqlRecognizers.size() == 1) { SQLRecognizer sqlRecognizer = sqlRecognizers.get(0); switch (sqlRecognizer.getSQLType()) { //下面根据是增、删、改、加锁查询、普通查询分别创建对应的处理器 case INSERT: executor = EnhancedServiceLoader.load(InsertExecutor.class, dbType, new Class[]{StatementProxy.class, StatementCallback.class, SQLRecognizer.class}, new Object[]{statementProxy, statementCallback, sqlRecognizer}); break; case UPDATE: executor = new UpdateExecutor<>(statementProxy, statementCallback, sqlRecognizer); break; case DELETE: executor = new DeleteExecutor<>(statementProxy, statementCallback, sqlRecognizer); break; case SELECT_FOR_UPDATE: executor = new SelectForUpdateExecutor<>(statementProxy, statementCallback, sqlRecognizer); break; default: executor = new PlainExecutor<>(statementProxy, statementCallback); break; } } else { // 此执行器可以处理一条SQL语句包含多个Delete、Update语句 executor = new MultiExecutor<>(statementProxy, statementCallback, sqlRecognizers); } } T rs; try { // 执行器执行 rs = executor.execute(args); } catch (Throwable ex) { if (!(ex instanceof SQLException)) { // Turn other exception into SQLException ex = new SQLException(ex); } throw (SQLException) ex; } return rs; } }
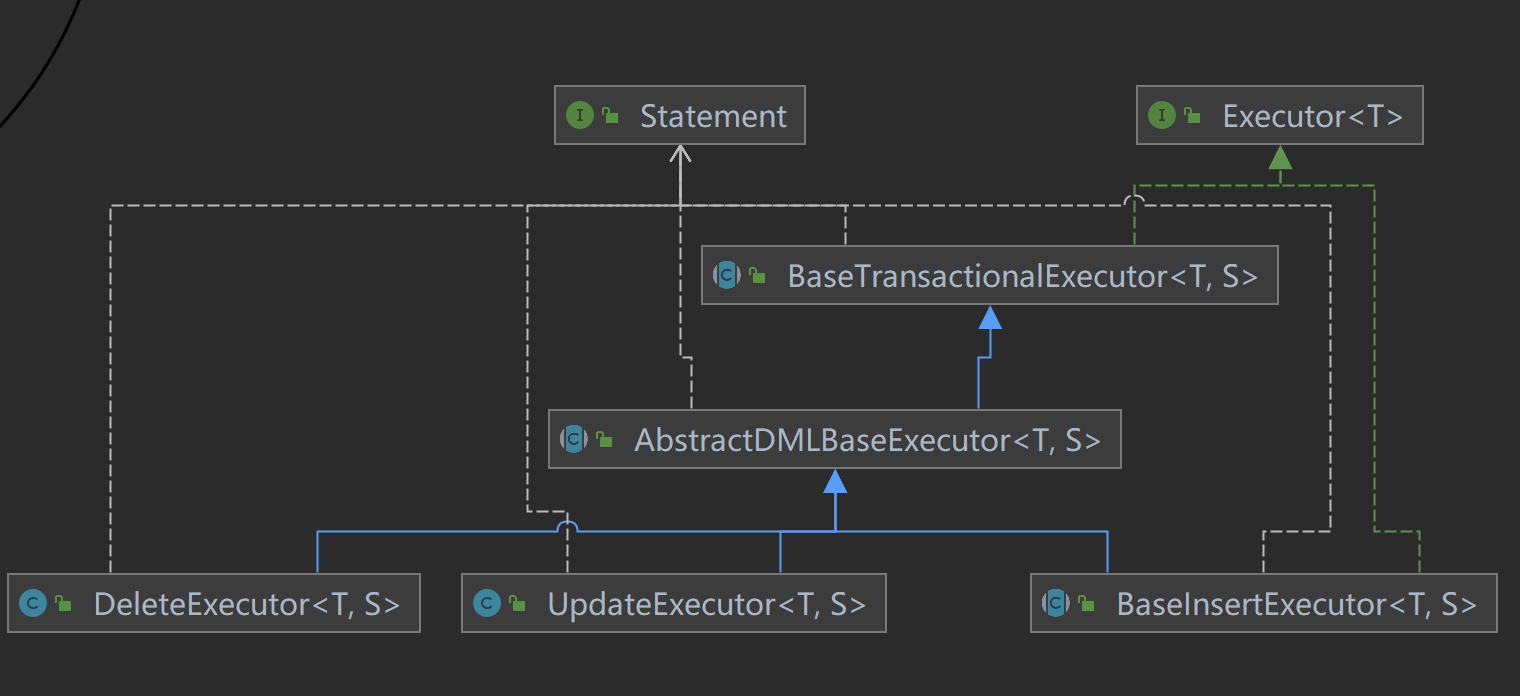
从ExecuteTemplate中可以看到,seata将SQL语句的执行委托给了不同的执行器。seata提供了6个执行器(模板模式),所有执行器的父类型为AbstractDMLBaseExecutor。
UpdateExecutor 执行update语句 InsertExecutor 执行insert语句 DeleteExecutor 执行delete语句 SelectForUpdateExecutor 执行select for update语句 PlainExecutor 执行普通查询语句 MultiExecutor 复合执行器,在一条SQL语句中执行多条语句
关系结构图
那我们继续向下看,这里我们要分析的就是executor.execute(args);方法,自然这里调用的就是父类的方法
1 2 3 4 5 6 7 8 9 10 11 @Override public T execute(Object... args) throws Throwable { String xid = RootContext.getXID(); if (xid != null) { // 获取xid statementProxy.getConnectionProxy().bind(xid); } // 设置全局锁 statementProxy.getConnectionProxy().setGlobalLockRequire(RootContext.requireGlobalLock()); return doExecute(args); }
向下来看doExecute()方法,AbstractDMLBaseExecutor重写的方法
1 2 3 4 5 6 7 8 9 @Override public T doExecute(Object... args) throws Throwable { AbstractConnectionProxy connectionProxy = statementProxy.getConnectionProxy(); if (connectionProxy.getAutoCommit()) { return executeAutoCommitTrue(args); } else { return executeAutoCommitFalse(args); } }
首先我们都清楚,数据库本身都是自动提交
1 2 3 4 5 6 7 8 9 @Override public T doExecute(Object... args) throws Throwable { AbstractConnectionProxy connectionProxy = statementProxy.getConnectionProxy(); if (connectionProxy.getAutoCommit()) { return executeAutoCommitTrue(args); } else { return executeAutoCommitFalse(args); } }
进入executeAutoCommitTrue()方法中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 protected T executeAutoCommitTrue(Object[] args) throws Throwable { ConnectionProxy connectionProxy = statementProxy.getConnectionProxy(); try { // 更改为手动提交 connectionProxy.changeAutoCommit(); return new LockRetryPolicy(connectionProxy).execute(() -> { // 调用手动提交方法 得到分支业务最终结果 T result = executeAutoCommitFalse(args); // 执行提交 connectionProxy.commit(); return result; }); } catch (Exception e) { // when exception occur in finally,this exception will lost, so just print it here LOGGER.error("execute executeAutoCommitTrue error:{}", e.getMessage(), e); if (!LockRetryPolicy.isLockRetryPolicyBranchRollbackOnConflict()) { connectionProxy.getTargetConnection().rollback(); } throw e; } finally { connectionProxy.getContext().reset(); connectionProxy.setAutoCommit(true); } }
然后我们查看connectionProxy.changeAutoCommit();更改为手动提交
1 2 3 4 5 6 7 8 9 10 11 12 13 14 protected T executeAutoCommitFalse(Object[] args) throws Exception { if (!JdbcConstants.MYSQL.equalsIgnoreCase(getDbType()) && isMultiPk()) { throw new NotSupportYetException("multi pk only support mysql!"); } // 前镜像 TableRecords beforeImage = beforeImage(); // 执行具体业余 T result = statementCallback.execute(statementProxy.getTargetStatement(), args); // 后镜像 TableRecords afterImage = afterImage(beforeImage); // 暂存UndoLog,为了在Commit的时候保存到数据库 prepareUndoLog(beforeImage, afterImage); return result; }
然后我们再回到executeAutoCommitTrue这个方法中向下看connectionProxy.commit();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Override public void commit() throws SQLException { try { LOCK_RETRY_POLICY.execute(() -> { // 具体执行 doCommit(); return null; }); } catch (SQLException e) { if (targetConnection != null && !getAutoCommit() && !getContext().isAutoCommitChanged()) { rollback(); } throw e; } catch (Exception e) { throw new SQLException(e); } }
进入到doCommit方法中
1 2 3 4 5 6 7 8 9 10 private void doCommit() throws SQLException { //判断是否存在全局事务 if (context.inGlobalTransaction()) { processGlobalTransactionCommit(); } else if (context.isGlobalLockRequire()) { processLocalCommitWithGlobalLocks(); } else { targetConnection.commit(); } }
此时很明显我们存在全局事务,所以进入到processGlobalTransactionCommit方法中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 private void processGlobalTransactionCommit() throws SQLException { try { // 注册分支 register(); } catch (TransactionException e) { recognizeLockKeyConflictException(e, context.buildLockKeys()); } try { //写入数据库undolog UndoLogManagerFactory.getUndoLogManager(this.getDbType()).flushUndoLogs(this); //执行原生提交 targetConnection.commit(); } catch (Throwable ex) { LOGGER.error("process connectionProxy commit error: {}", ex.getMessage(), ex); report(false); throw new SQLException(ex); } if (IS_REPORT_SUCCESS_ENABLE) { report(true); } context.reset(); }
其中的register方法就是注册分支事务的方法,同时还有把undolog写入数据库和执行提交的操作
1 2 3 4 5 6 7 8 9 10 // 注册分支事务,生成分支事务id private void register() throws TransactionException { if (!context.hasUndoLog() || !context.hasLockKey()) { return; } // 注册分支事务 Long branchId = DefaultResourceManager.get().branchRegister(BranchType.AT, getDataSourceProxy().getResourceId(), null, context.getXid(), null, context.buildLockKeys()); context.setBranchId(branchId); }
接下来我们就具体看看写入数据库的方法flushUndoLogs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @Override public void flushUndoLogs(ConnectionProxy cp) throws SQLException { ConnectionContext connectionContext = cp.getContext(); if (!connectionContext.hasUndoLog()) { return; } String xid = connectionContext.getXid(); long branchId = connectionContext.getBranchId(); BranchUndoLog branchUndoLog = new BranchUndoLog(); branchUndoLog.setXid(xid); branchUndoLog.setBranchId(branchId); branchUndoLog.setSqlUndoLogs(connectionContext.getUndoItems()); UndoLogParser parser = UndoLogParserFactory.getInstance(); byte[] undoLogContent = parser.encode(branchUndoLog); CompressorType compressorType = CompressorType.NONE; if (needCompress(undoLogContent)) { compressorType = ROLLBACK_INFO_COMPRESS_TYPE; undoLogContent = CompressorFactory.getCompressor(compressorType.getCode()).compress(undoLogContent); } if (LOGGER.isDebugEnabled()) { LOGGER.debug("Flushing UNDO LOG: {}", new String(undoLogContent, Constants.DEFAULT_CHARSET)); } // 写入数据库具体位置 insertUndoLogWithNormal(xid, branchId, buildContext(parser.getName(), compressorType), undoLogContent, cp.getTargetConnection()); }
具体写入方法,此时我们使用的是MySql,所以执行的是MySql实现类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @Override protected void insertUndoLogWithNormal(String xid, long branchId, String rollbackCtx, byte[] undoLogContent, Connection conn) throws SQLException { insertUndoLog(xid, branchId, rollbackCtx, undoLogContent, State.Normal, conn); } @Override protected void insertUndoLogWithGlobalFinished(String xid, long branchId, UndoLogParser parser, Connection conn) throws SQLException { insertUndoLog(xid, branchId, buildContext(parser.getName(), CompressorType.NONE), parser.getDefaultContent(), State.GlobalFinished, conn); } // 具体写入 private void insertUndoLog(String xid, long branchId, String rollbackCtx, byte[] undoLogContent, State state, Connection conn) throws SQLException { try (PreparedStatement pst = conn.prepareStatement(INSERT_UNDO_LOG_SQL)) { pst.setLong(1, branchId); pst.setString(2, xid); pst.setString(3, rollbackCtx); pst.setBytes(4, undoLogContent); pst.setInt(5, state.getValue()); pst.executeUpdate(); } catch (Exception e) { if (!(e instanceof SQLException)) { e = new SQLException(e); } throw (SQLException) e; } }
原理图地址: https://www.processon.com/view/link/6213d58f1e0853078013c58f