数据结构与算法 线性表—栈
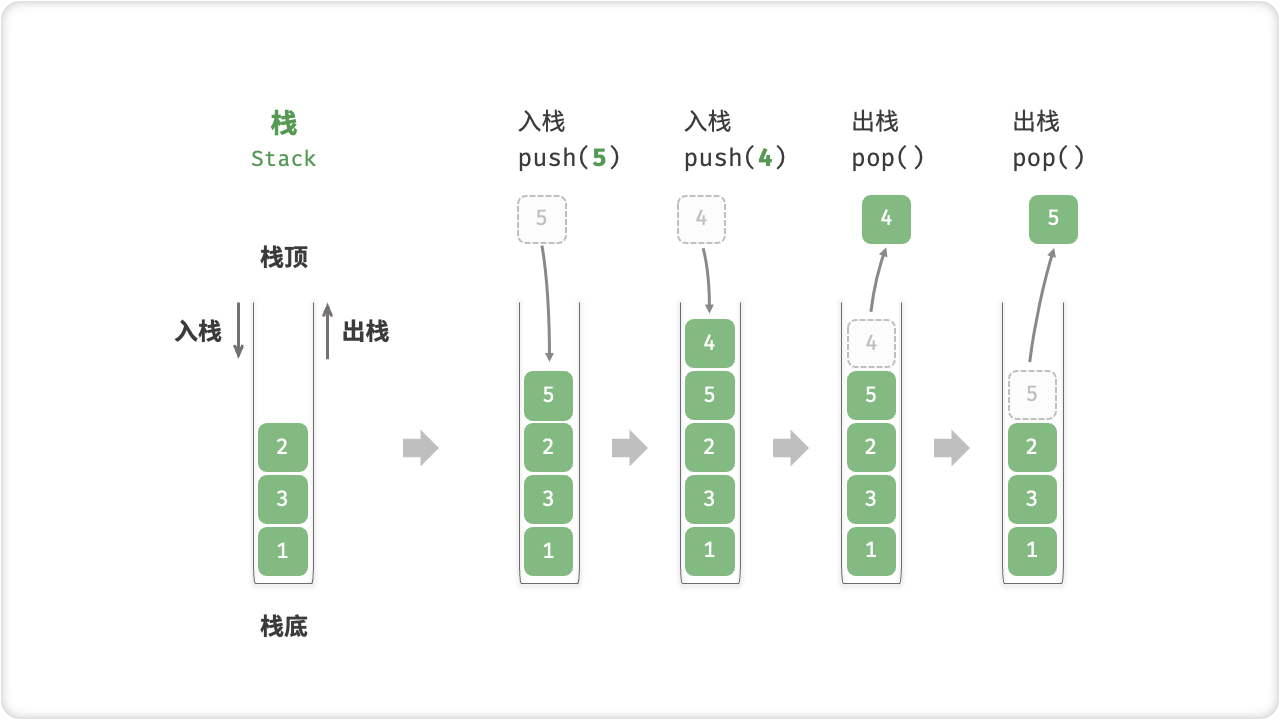
「栈 Stack」是一种遵循先入后出(First In, Last Out)原则的线性数据结构。
我们可以将栈类比为桌面上的一摞盘子,如果需要拿出底部的盘子,则需要先将上面的盘子依次取出。我们将盘子替换为各种类型的元素(如整数、字符、对象等),就得到了栈数据结构。
在栈中,我们把堆叠元素的顶部称为「栈顶」,底部称为「栈底」。将把元素添加到栈顶的操作叫做「入栈」,而删除栈顶元素的操作叫做「出栈」。
栈常用操作
栈的常用操作如下表所示,具体的方法名需要根据所使用的编程语言来确定。在此,我们以常见的 push() , pop() , peek() 命名为例。
| 方法 | 描述 | 时间复杂度 |
|---|---|---|
| push() | 元素入栈(添加至栈顶) | O(1) |
| pop() | 栈顶元素出栈 | O(1) |
| peek() | 访问栈顶元素 | O(1) |
栈的实现
栈遵循先入后出的原则,因此我们只能在栈顶添加或删除元素。然而,数组和链表都可以在任意位置添加和删除元素,因此栈可以被视为一种受限制的数组或链表。换句话说,我们可以“屏蔽”数组或链表的部分无关操作,使其对外表现的逻辑符合栈的特性。
基于链表的实现
使用链表来实现栈时,我们可以将链表的头节点视为栈顶,尾节点视为栈底。
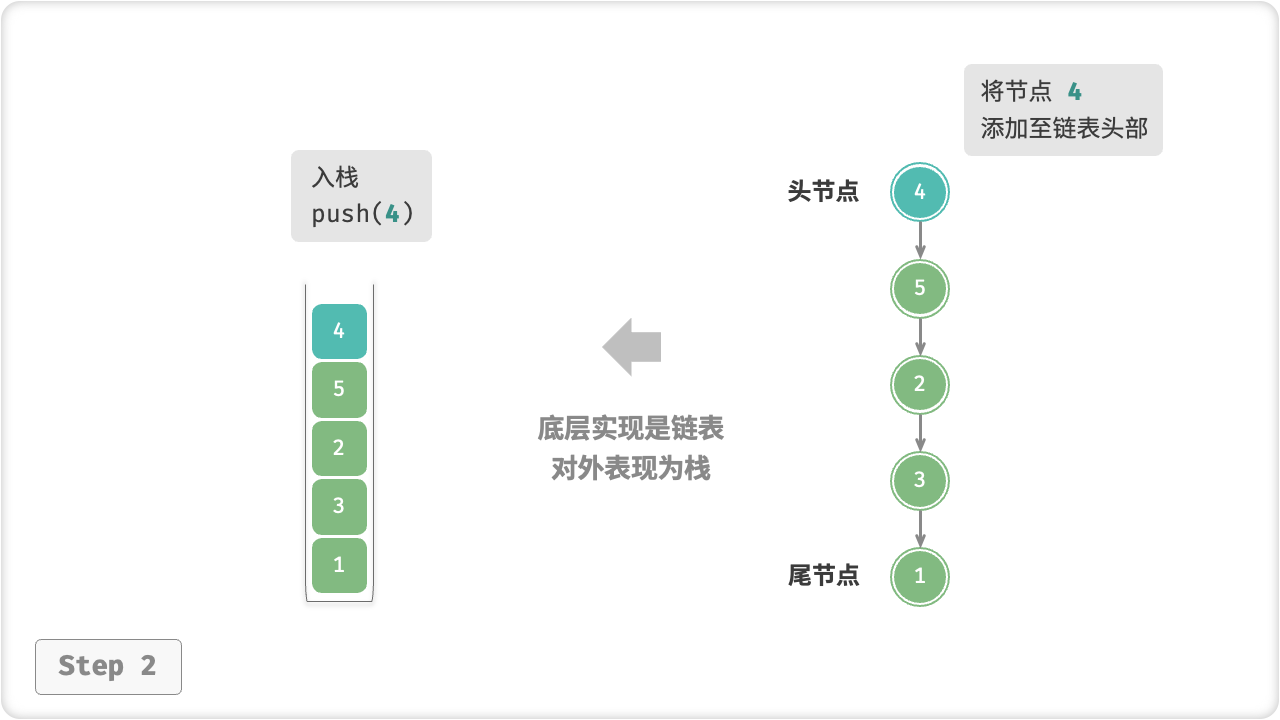
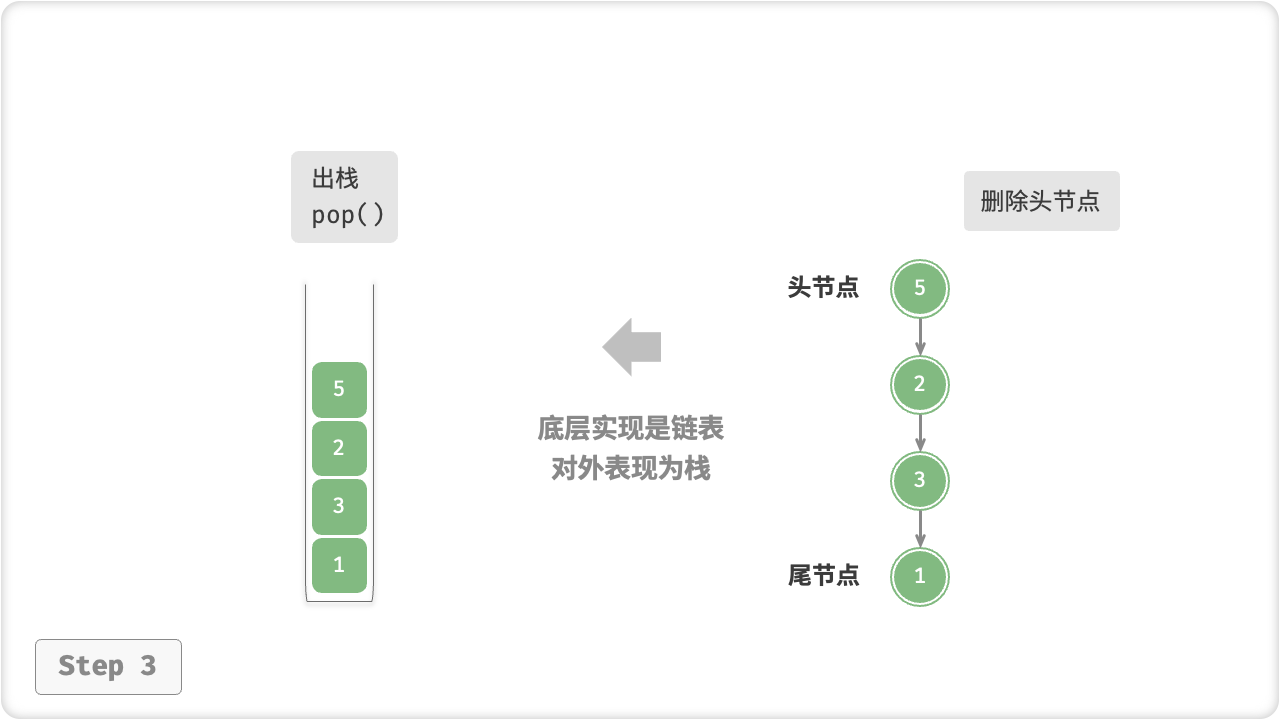
对于入栈操作,我们只需将元素插入链表头部,这种节点插入方法被称为“头插法”。而对于出栈操作,只需将头节点从链表中删除即可。 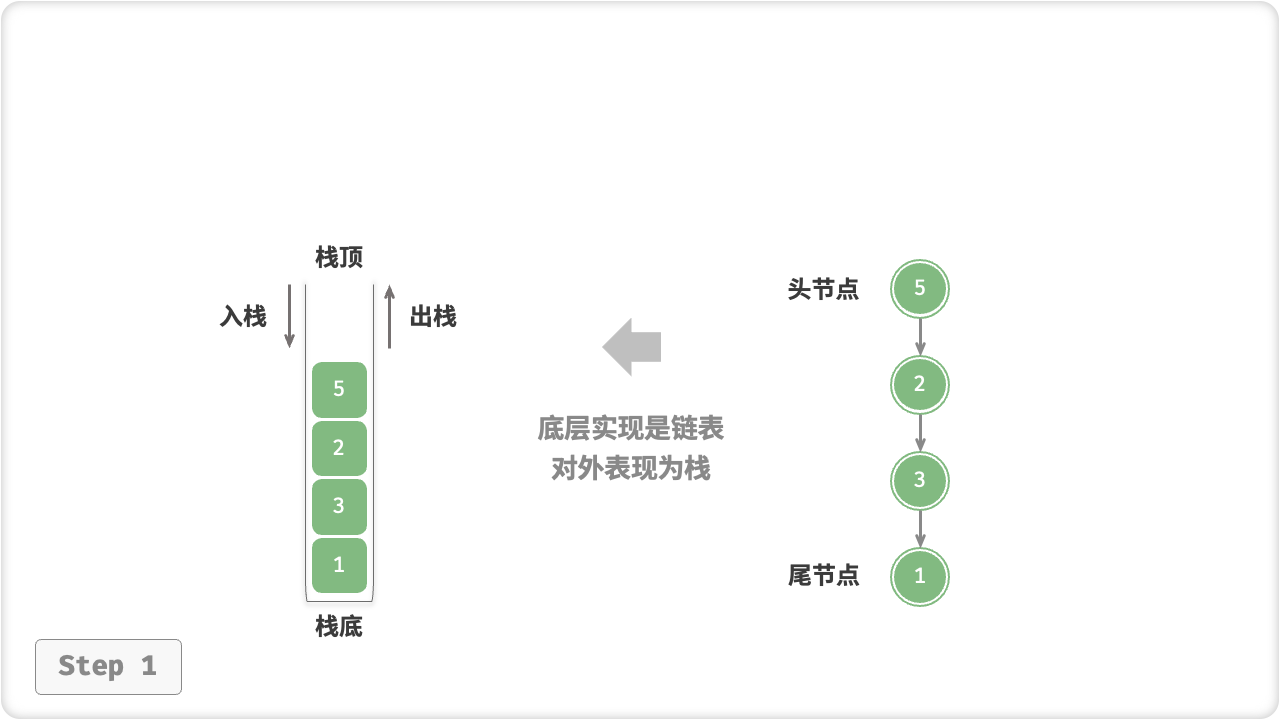
入栈push()
出栈pop()
基于数组的实现
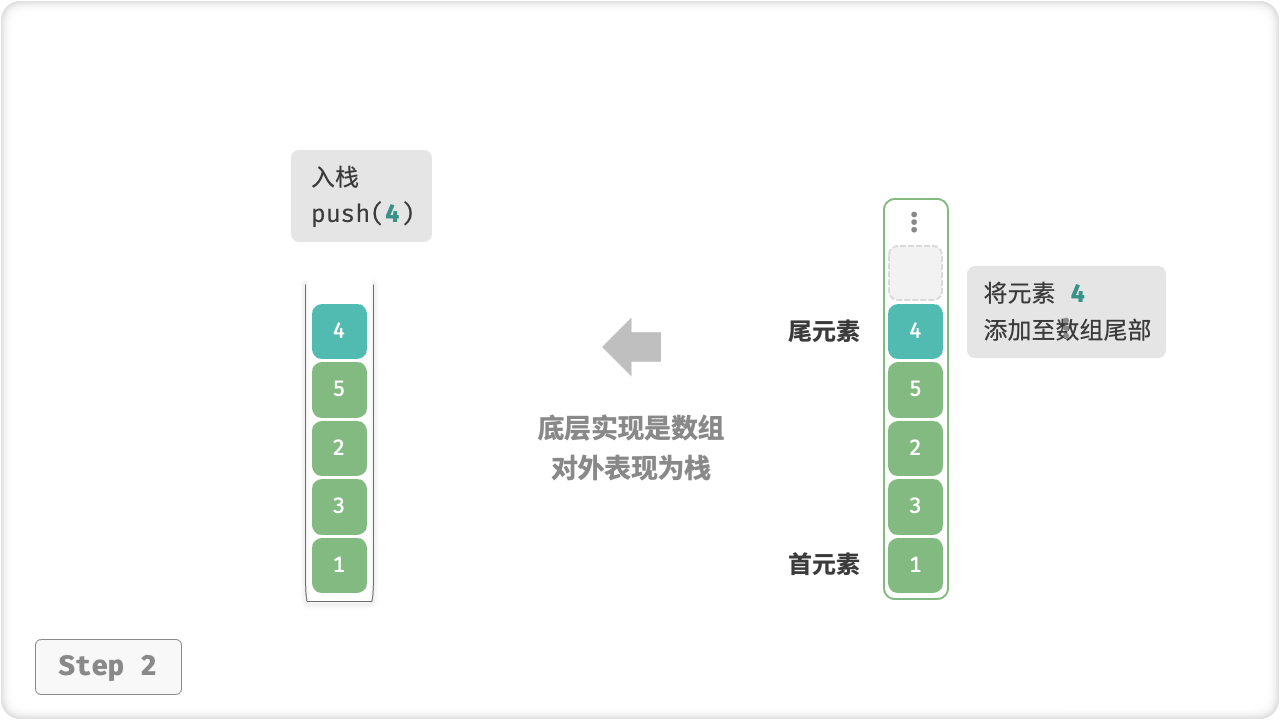
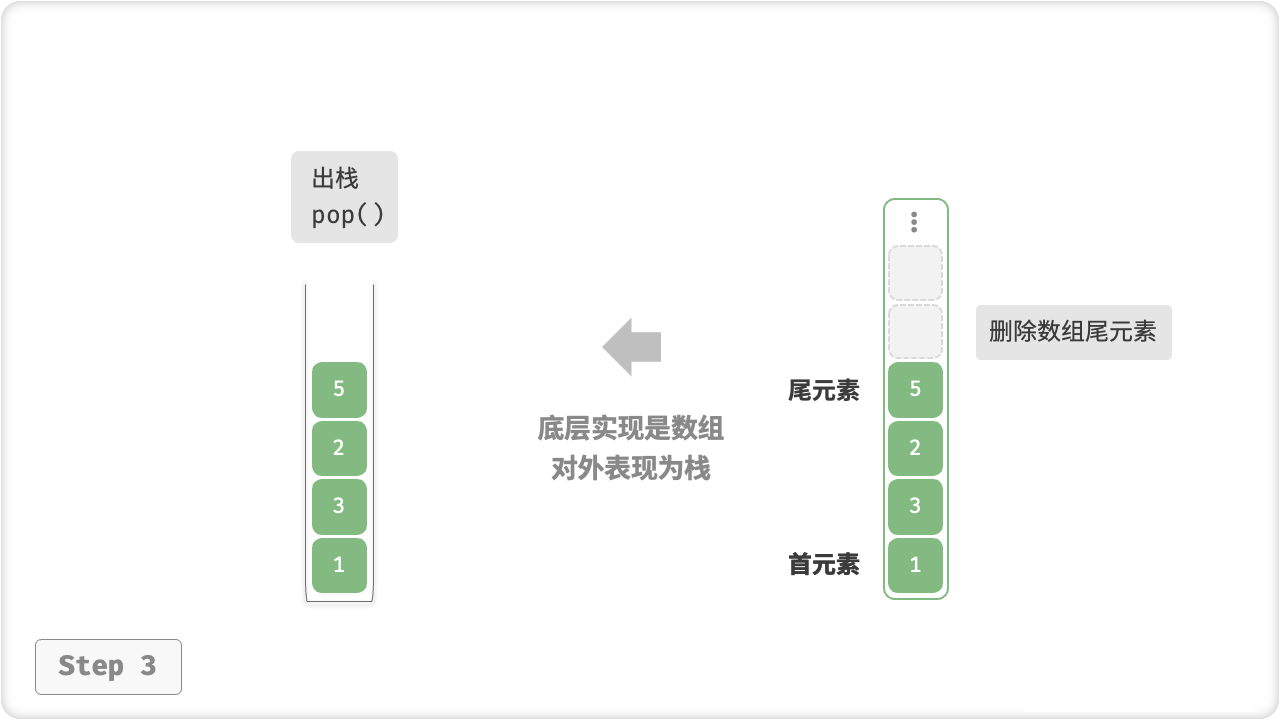
在基于「数组」实现栈时,我们可以将数组的尾部作为栈顶。在这样的设计下,入栈与出栈操作就分别对应在数组尾部添加元素与删除元素,时间复杂度都为 O(1) 。
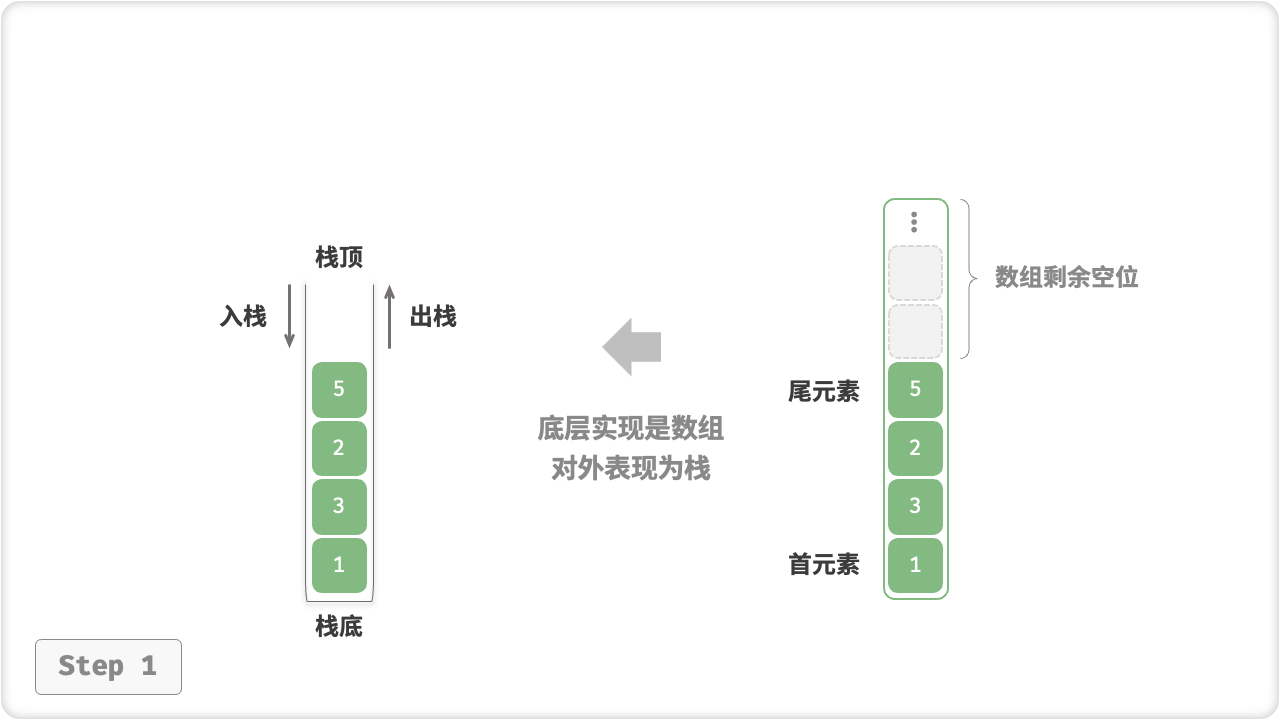
入栈push()
出栈pop()
由于入栈的元素可能会源源不断地增加,因此我们可以使用动态数组,这样就无需自行处理数组扩容问题。
两种实现对比
支持操作
两种实现都支持栈定义中的各项操作。数组实现额外支持随机访问,但这已超出了栈的定义范畴,因此一般不会用到。
时间效率
在基于数组的实现中,入栈和出栈操作都是在预先分配好的连续内存中进行,具有很好的缓存本地性,因此效率较高。然而,如果入栈时超出数组容量,会触发扩容机制,导致该次入栈操作的时间复杂度变为 O(n)。
在链表实现中,链表的扩容非常灵活,不存在上述数组扩容时效率降低的问题。但是,入栈操作需要初始化节点对象并修改指针,因此效率相对较低。不过,如果入栈元素本身就是节点对象,那么可以省去初始化步骤,从而提高效率。
综上所述,当入栈与出栈操作的元素是基本数据类型(如 int , double )时,我们可以得出以下结论:
- 基于数组实现的栈在触发扩容时效率会降低,但由于扩容是低频操作,因此平均效率更高;
- 基于链表实现的栈可以提供更加稳定的效率表现;
空间效率
在初始化列表时,系统会为列表分配“初始容量”,该容量可能超过实际需求。并且,扩容机制通常是按照特定倍率(例如 2 倍)进行扩容,扩容后的容量也可能超出实际需求。因此,基于数组实现的栈可能造成一定的空间浪费。
然而,由于链表节点需要额外存储指针,因此链表节点占用的空间相对较大。
综上,我们不能简单地确定哪种实现更加节省内存,需要针对具体情况进行分析。
栈典型应用
- 浏览器中的后退与前进、软件中的撤销与反撤销。每当我们打开新的网页,浏览器就会将上一个网页执行入栈,这样我们就可以通过「后退」操作回到上一页面。后退操作实际上是在执行出栈。如果要同时支持后退和前进,那么需要两个栈来配合实现。
- 程序内存管理。每次调用函数时,系统都会在栈顶添加一个栈帧,用于记录函数的上下文信息。在递归函数中,向下递推阶段会不断执行入栈操作,而向上回溯阶段则会执行出栈操作。