算法与数据结构 排序算法
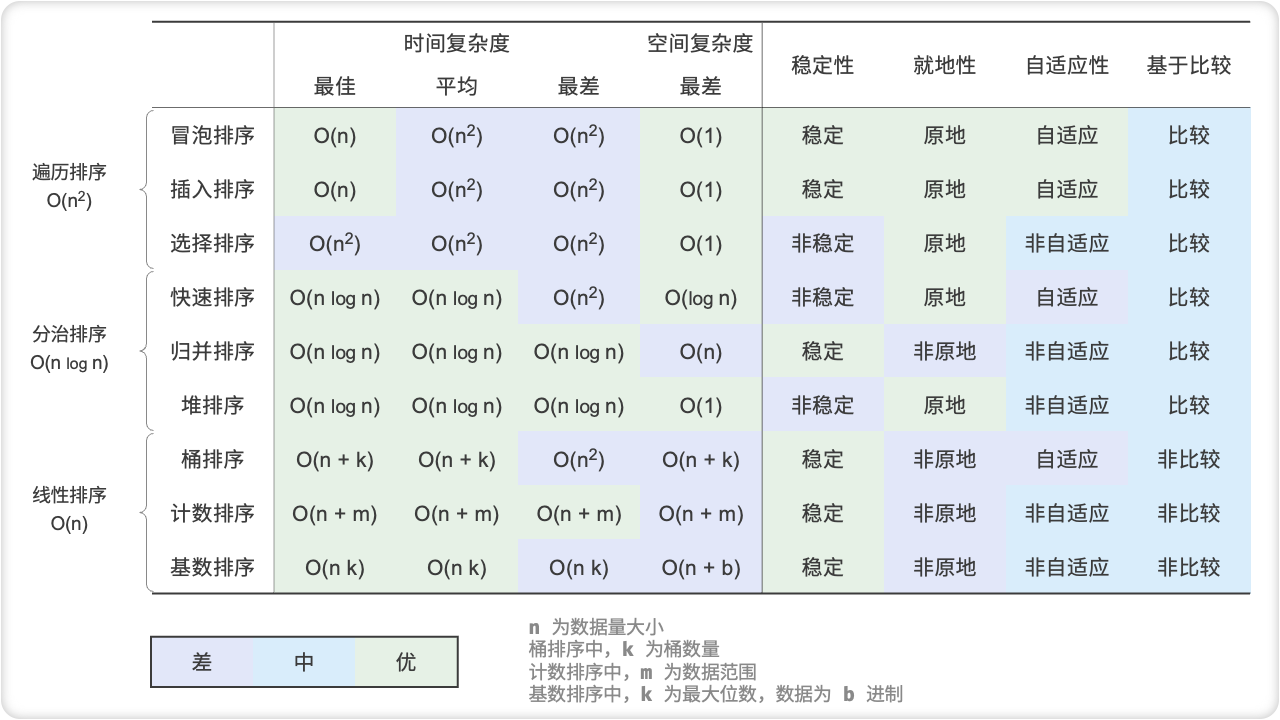
常见的排序算法
选择排序是一种基于比较的排序算法,其基本思想是在每个回合中从未排序部分找出最小(或最大)元素,将其与已排序部分的末尾进行交换,以此类推,直至整个序列有序。该算法具有简单直观的特点,但时间复杂度较高,为O(n²),且不具备稳定性。
冒泡排序通过交换相邻元素来实现排序。通过添加一个标志位来实现提前返回,我们可以将冒泡排序的最佳时间复杂度优化到 O(n) 。
插入排序每轮将未排序区间内的元素插入到已排序区间的正确位置,从而完成排序。虽然插入排序的时间复杂度为 O(n²) ,但由于单元操作相对较少,它在小数据量的排序任务中非常受欢迎。
快速排序基于哨兵划分操作实现排序。在哨兵划分中,有可能每次都选取到最差的基准数,导致时间复杂度劣化至 $O(n^2)$ 。引入中位数基准数或随机基准数可以降低这种劣化的概率。尾递归方法可以有效地减少递归深度,将空间复杂度优化到 O(logn) 。
归并排序包括划分和合并两个阶段,典型地体现了分治策略。在归并排序中,排序数组需要创建辅助数组,空间复杂度为 O(n) ;然而排序链表的空间复杂度可以优化至 O(1) 。
堆排序是一种基于比较的排序算法,其核心思想是利用完全二叉堆这种数据结构特性对数据进行调整。首先构建一个大顶堆(或小顶堆),保证父节点的值大于(或小于)其子节点的值,然后将堆顶元素(最大或最小元素)与数组末尾元素交换,接着对剩余元素重新调整为堆,如此反复执行交换和调整的过程,直到整个序列有序。堆排序的时间复杂度为O(n log n),并且是不稳定的排序算法。
桶排序包含三个步骤:数据分桶、桶内排序和合并结果。它同样体现了分治策略,适用于数据体量很大的情况。桶排序的关键在于对数据进行平均分配。
计数排序是桶排序的一个特例,它通过统计数据出现的次数来实现排序。计数排序适用于数据量大但数据范围有限的情况,并且要求数据能够转换为正整数。
基数排序通过逐位排序来实现数据排序,要求数据能够表示为固定位数的数字。
排序通过逐位排序来实现数据排序,要求数据能够表示为固定位数的数字。
排序算法对比