数据结构与算法 排序算法-快速排序
「快速排序 Quick Sort」是一种基于分治思想的排序算法,运行高效,应用广泛。
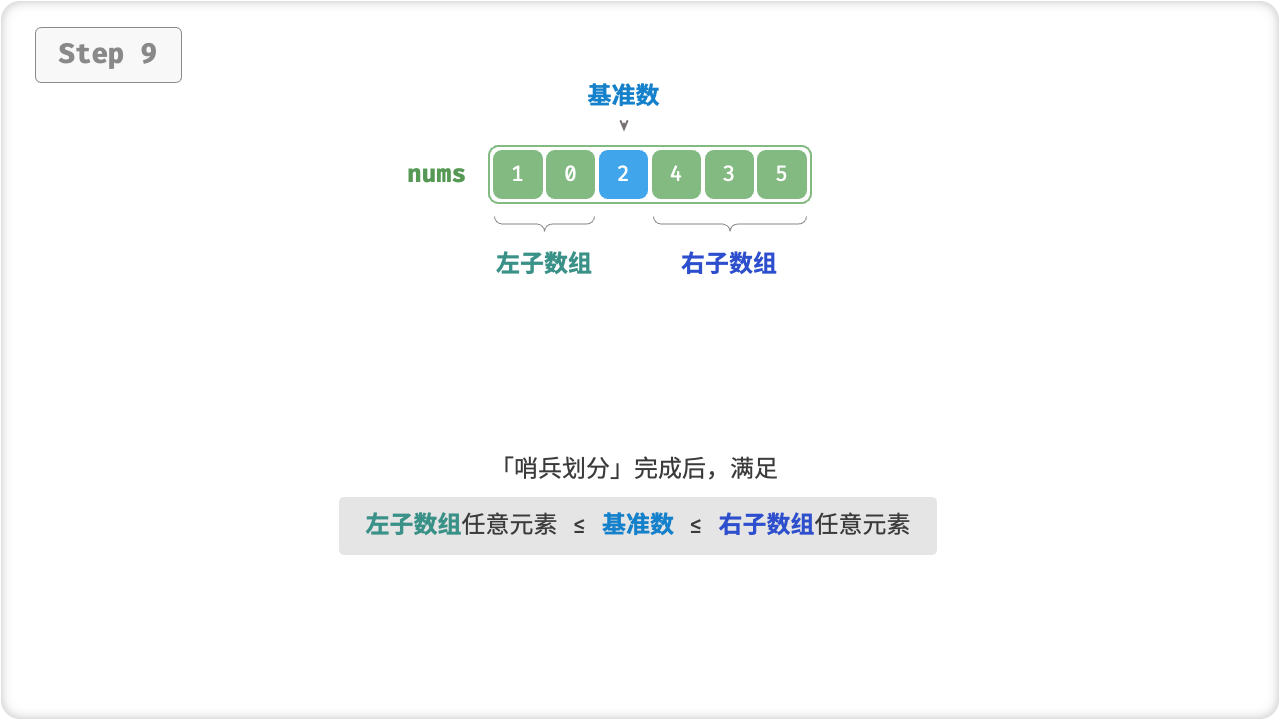
快速排序的核心操作是「哨兵划分」,其目标是:选择数组中的某个元素作为“基准数”,将所有小于基准数的元素移到其左侧,而大于基准数的元素移到其右侧。具体来说,哨兵划分的流程为:
- 选取数组最左端元素作为基准数,初始化两个指针
i和j分别指向数组的两端; - 设置一个循环,在每轮中使用
i(j)分别寻找第一个比基准数大(小)的元素,然后交换这两个元素; - 循环执行步骤
2.,直到i和j相遇时停止,最后将基准数交换至两个子数组的分界线;
哨兵划分完成后,原数组被划分成三部分:左子数组、基准数、右子数组,且满足“左子数组任意元素 ≤ 基准数 ≤ 右子数组任意元素”。因此,我们接下来只需对这两个子数组进行排序。
1

2

3

4

5

6

7

8

9
快速排序的分治思想
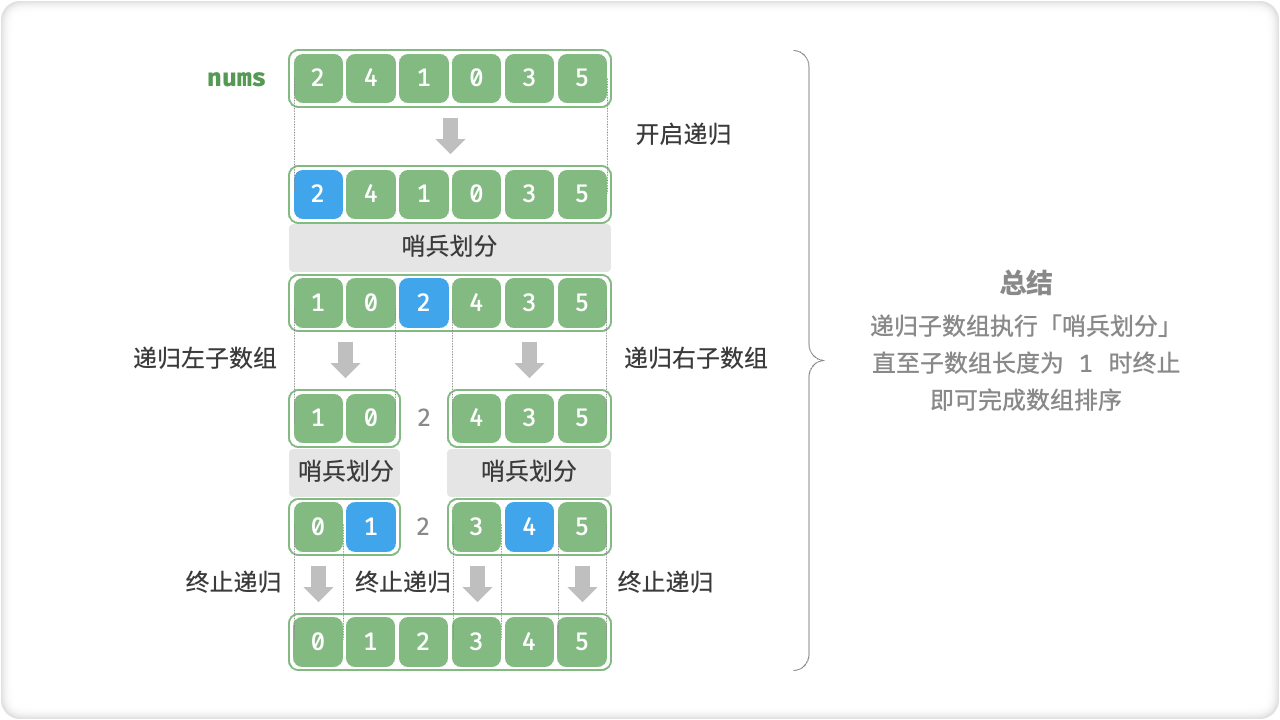
哨兵划分的实质是将一个较长数组的排序问题简化为两个较短数组的排序问题。
算法流程
- 首先,对原数组执行一次「哨兵划分」,得到未排序的左子数组和右子数组;
- 然后,对左子数组和右子数组分别递归执行「哨兵划分」;
- 持续递归,直至子数组长度为 1 时终止,从而完成整个数组的排序;
算法特性
- 时间复杂度 O(nlog n) 、自适应排序 :在平均情况下,哨兵划分的递归层数为log n ,每层中的总循环数为 n ,总体使用 O(nlog n) 时间。在最差情况下,每轮哨兵划分操作都将长度为 n 的数组划分为长度为 0 和 n - 1 的两个子数组,此时递归层数达到 n 层,每层中的循环数为 n ,总体使用 O(n^2) 时间。
- 空间复杂度 O(n) 、原地排序 :在输入数组完全倒序的情况下,达到最差递归深度 n ,使用 O(n) 栈帧空间。排序操作是在原数组上进行的,未借助额外数组。
- 非稳定排序:在哨兵划分的最后一步,基准数可能会被交换至相等元素的右侧。
快排为什么快?
从名称上就能看出,快速排序在效率方面应该具有一定的优势。尽管快速排序的平均时间复杂度与「归并排序」和「堆排序」相同,但通常快速排序的效率更高,原因如下:
- 出现最差情况的概率很低:虽然快速排序的最差时间复杂度为 O(n^2) ,没有归并排序稳定,但在绝大多数情况下,快速排序能在 O(nlog n) 的时间复杂度下运行。
- 缓存使用效率高:在执行哨兵划分操作时,系统可将整个子数组加载到缓存,因此访问元素的效率较高。而像「堆排序」这类算法需要跳跃式访问元素,从而缺乏这一特性。
- 复杂度的常数系数低:在上述三种算法中,快速排序的比较、赋值、交换等操作的总数量最少。这与「插入排序」比「冒泡排序」更快的原因类似。
基准数优化
快速排序在某些输入下的时间效率可能降低。举一个极端例子,假设输入数组是完全倒序的,由于我们选择最左端元素作为基准数,那么在哨兵划分完成后,基准数被交换至数组最右端,导致左子数组长度为 n - 1 、右子数组长度为 0 。如此递归下去,每轮哨兵划分后的右子数组长度都为 0 ,分治策略失效,快速排序退化为「冒泡排序」。
为了尽量避免这种情况发生,我们可以优化哨兵划分中的基准数的选取策略。例如,我们可以随机选取一个元素作为基准数。然而,如果运气不佳,每次都选到不理想的基准数,效率仍然不尽如人意。
需要注意的是,编程语言通常生成的是“伪随机数”。如果我们针对伪随机数序列构建一个特定的测试样例,那么快速排序的效率仍然可能劣化。
为了进一步改进,我们可以在数组中选取三个候选元素(通常为数组的首、尾、中点元素),并将这三个候选元素的中位数作为基准数。这样一来,基准数“既不太小也不太大”的概率将大幅提升。当然,我们还可以选取更多候选元素,以进一步提高算法的稳健性。采用这种方法后,时间复杂度劣化至 O(n^2) 的概率大大降低。
尾递归优化
在某些输入下,快速排序可能占用空间较多。以完全倒序的输入数组为例,由于每轮哨兵划分后右子数组长度为 0 ,递归树的高度会达到 n - 1 ,此时需要占用 O(n) 大小的栈帧空间。
为了防止栈帧空间的累积,我们可以在每轮哨兵排序完成后,比较两个子数组的长度,仅对较短的子数组进行递归。由于较短子数组的长度不会超过 n/2 ,因此这种方法能确保递归深度不超过log n ,从而将最差空间复杂度优化至 O(log n) 。