Windows常用运行LLM工具
llama.cpp
介绍
llama.cpp 立志于在纯 C/C++ 中推断 Meta 的 LLaMA 模型(及其他模型)
仓库地址:https://github.com/ggerganov/llama.cpp
llama.cpp 的主要目标是在本地和云端的各种硬件上以最少的设置和最先进的性能实现 LLM 推理。
- 没有任何依赖的纯 C/C++ 实现
- Apple 芯片是一等公民 - 通过 ARM NEON、Accelerate 和 Metal 框架进行优化
- 对 x86 架构的 AVX、AVX2 和 AVX512 支持
- 1.5 位、2 位、3 位、4 位、5 位、6 位和 8 位整数量化,可加快推理速度并减少内存使用
- 用于在 NVIDIA GPU 上运行 LLMs 的自定义 CUDA 内核(通过 HIP 支持 AMD GPU)
- Vulkan、SYCL 和(部分)OpenCL 后端支持
- CPU+GPU 混合推理,部分加速大于 VRAM 总容量的模型
支持目前绝大多数的开源模型。
http服务
llama.cpp Web 服务器是一个轻量级 OpenAI API 兼容的 HTTP 服务器,可用于服务本地模型并轻松将它们连接到现有客户端。
安装官方编译版本
https://github.com/ggerganov/llama.cpp/releases 下载最新编译好的可执行文件
本地编译
量化
以 7B 为例
| Model | Measure | FP16 | Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 |
|---|---|---|---|---|---|---|---|
| 7B | perplexity | 5.9066 | 6.1565 | 6.0912 | 5.9862 | 5.9481 | 5.9070 |
| 7B | file size | 13.0G | 3.5G | 3.9G | 4.3G | 4.7G | 6.7G |
| 7B | ms/tok @ 4th | 127 | 55 | 54 | 76 | 83 | 72 |
| 7B | ms/tok @ 8th | 122 | 43 | 45 | 52 | 56 | 67 |
| 7B | bits/weight | 16.0 | 4.5 | 5.0 | 5.5 | 6.0 | 8.5 |
以perplexity(复杂度(PPL)是评估语言模型最常用的指标之一)衡量模型性能的话,q8_0和FP16相差无几。但模型却大大缩小了,并带来了生成速度的大幅提升。13B,30B,65B 的量化同样符合这个规律
Memory/Disk Requirements
| 模型 | 原始尺寸 | 量化大小(4 位) |
|---|---|---|
| 7B | 13GB | 3.9GB |
| 13B | 24GB | 7.8GB |
| 30B | 60GB | 19.5GB |
| 65B | 120GB | 38.5GB |
环境:
- linux操作系统、cuda11.8、N卡7卡12G、X86架构
运行前请确保:
- 模型量化过程需要将未量化模型全部载入内存,请确保有足够可用内存(7B版本需要13G以上)
- 加载使用Q4量化后的模型时(例如7B版本),确保本机可用内存大于4-6G(受上下文长度影响)
- 系统应有make(MacOS/Linux自带)或cmake(Windows需自行安装)编译工具
- 推荐使用Python 3.9或3.10编译运行llama.cpp工具(因为sentencepiece还不支持3.11)
1、克隆和编译llama.cpp
- 拉取最新版llama.cpp仓库代码
1 | $ git clone https://github.com/ggerganov/llama.cpp |
- 对llama.cpp项目进行编译,生成
./main(用于推理)和./quantize(用于量化)二进制文件。
1 | $ make #M系列芯片默认使用Metal这样编译的项目好像只能在CPU上允许,如果想用GPU加速,参考下面的cuBLAS编译方式 |
- Windows/Linux用户:推荐与BLAS(或cuBLAS如果有GPU)一起编译,可以提高prompt处理速度,参考:llama.cpp#blas-build
- macOS用户:无需额外操作,llama.cpp已对ARM NEON做优化,并且已自动启用BLAS。M系列芯片推荐使用Metal启用GPU推理,显著提升速度。只需将编译命令改为:
LLAMA_METAL=1 make,参考llama.cpp#metal-buildr
- 编译项目:
输入 make
- 如果遇到报错,请make clean 后重试即可
报错:使用cuBLAS 一起编译 make LLAMA_CUBLAS=1
make: nvcc: No such file or directory
make: nvcc: No such file or directory
make: *** [Makefile:263: ggml-cuda.o] Error 127
(llamacpp) xxxx@gpuserver:~/LLM/llama.cpp$ nvcc
Command ‘nvcc’ not found, but can be installed with:
apt install nvidia-cuda-toolkit
Please ask your administrator.
应该跟没有装nvcc这个包有关系
2、生成量化版本模型
llama.cpp支持.pth文件(参考这里)以及huggingface格式.bin的转换。
将完整模型权重转换为GGML的FP16格式,生成文件路径为models/llama-2-7b-hf/ggml-model-f16.bin。进一步对FP16模型进行4-bit量化,生成量化模型文件路径为models/llama-2-7b-hf/ggml-model-q4_0.bin。不同量化方法的性能对比见本Wiki最后部分。
1 | #把模型参数放到models文件夹下 |
- 当然可以-h 查看脚本的一些超参数
大多数使用 argparse 的脚本会在命令行中提供 -h 或 --help 参数,用于显示参数的帮助信息。尝试运行以下命令,看看是否可以获取参数的使用信息:
添加 -h 或 –help 参数运行脚本
4bit量化模型大小为3.8G

3、加载模型(在CPU上)
运行./main二进制文件,-m命令指定 Q4量化模型(也可加载ggml-FP16的模型)。
1 | # run the inference 推理 |
由于项目编译的方式,我只能在CPU上load,如果想用GPU加速,放在GPU上,需要更换1中的编译方式!
GPU推理:通过Metal编译则只需在
./main中指定-ngl 1;cuBLAS编译需要指定offload层数,例如-ngl 40表示offload 40层模型参数到GPU
在支持 Metal 的情况下,可以使用 –gpu-layers|-ngl 命令行参数启用 GPU 推理。任何大于 0 的值都会将计算卸载到 GPU
q4量化占3G多,f16量化13G多(输出慢一些)
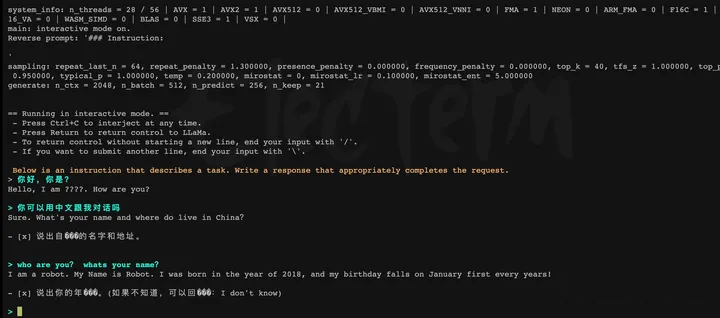
instruct方式测试llama2-7B-hf 基座模型
在提示符 > 之后输入你的prompt,command+c中断输出,多行信息以\作为行尾。如需查看帮助和参数说明,请执行./main -h命令。
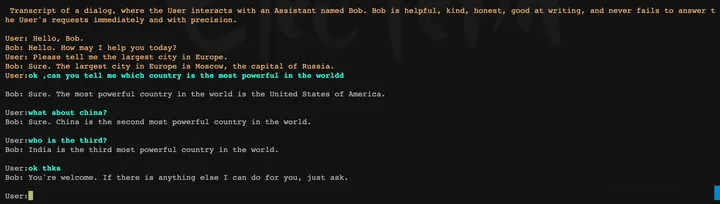
chat with bob ,英文非常ok
比较重要的参数:
- -ins 启动类ChatGPT的对话交流模式
- -f 指定prompt模板,alpaca模型请加载prompts/alpaca.txt 指令模板
- -c 控制上下文的长度,值越大越能参考更长的对话历史(默认:512)
- -n 控制回复生成的最大长度(默认:128)
- –repeat_penalty 控制生成回复中对重复文本的惩罚力度
- –temp 温度系数,值越低回复的随机性越小,反之越大
- –top_p, top_k 控制解码采样的相关参数
- -b 控制batch size(默认:512)
- -t 控制线程数量(默认:8),可适当增加
评估命令
1 | $ ./perplexity -m ./models/llama-2-7b-hf/ggml-model-q4_0.bin -f test.txt -c 4096 -eps 1e-5 -ngl 1 |
- 默认的量化方法为q4_0,虽然速度最快但损失也较大,推荐使用Q4_K作为替代
- 线程数
-t与物理核心数一致时速度最快,超过之后速度反而变慢(M1 Max上从8改到10之后耗时变为3倍) - 机器资源够用且对速度要求不是那么苛刻的情况下可以使用q8_0或Q6_K,非常接近F16模型的效果
4、API 方式调
调用手册:https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md
1 | #启动server 参数请./server -h 查看 |