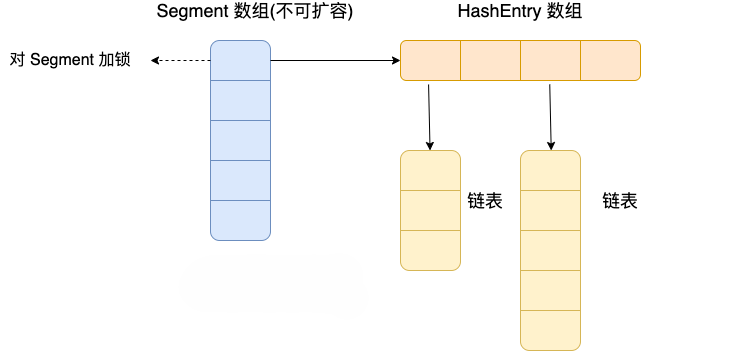
/** * Maps the specified key to the specified value in this table. * Neither the key nor the value can be null. * * <p> The value can be retrieved by calling the <tt>get</tt> method * with a key that is equal to the original key. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt> * @throws NullPointerException if the specified key or value is null */ public V put(K key, V value) { Segment<K,V> s; if (value == null) thrownewNullPointerException(); inthash= hash(key); // hash 值无符号右移 28位(初始化时获得),然后与 segmentMask=15 做与运算 // 其实也就是把高4位与segmentMask(1111)做与运算 intj= (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment // 如果查找到的 Segment 为空,初始化 s = ensureSegment(j); return s.put(key, hash, value, false); }
/** * Returns the segment for the given index, creating it and * recording in segment table (via CAS) if not already present. * * @param k the index * @return the segment */ @SuppressWarnings("unchecked") private Segment<K,V> ensureSegment(int k) { final Segment<K,V>[] ss = this.segments; longu= (k << SSHIFT) + SBASE; // raw offset Segment<K,V> seg; // 判断 u 位置的 Segment 是否为null if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { Segment<K,V> proto = ss[0]; // use segment 0 as prototype // 获取0号 segment 里的 HashEntry<K,V> 初始化长度 intcap= proto.table.length; // 获取0号 segment 里的 hash 表里的扩容负载因子,所有的 segment 的 loadFactor 是相同的 floatlf= proto.loadFactor; // 计算扩容阀值 intthreshold= (int)(cap * lf); // 创建一个 cap 容量的 HashEntry 数组 HashEntry<K,V>[] tab = (HashEntry<K,V>[])newHashEntry[cap]; if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck // 再次检查 u 位置的 Segment 是否为null,因为这时可能有其他线程进行了操作 Segment<K,V> s = newSegment<K,V>(lf, threshold, tab); // 自旋检查 u 位置的 Segment 是否为null while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // 使用CAS 赋值,只会成功一次 if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s)) break; } } } return seg; }
上面的源码分析了 ConcurrentHashMap 在 put 一个数据时的处理流程,下面梳理下具体流程。
privatevoidrehash(HashEntry<K,V> node) { HashEntry<K,V>[] oldTable = table; // 老容量 intoldCapacity= oldTable.length; // 新容量,扩大两倍 intnewCapacity= oldCapacity << 1; // 新的扩容阀值 threshold = (int)(newCapacity * loadFactor); // 创建新的数组 HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) newHashEntry[newCapacity]; // 新的掩码,默认2扩容后是4,-1是3,二进制就是11。 intsizeMask= newCapacity - 1; for (inti=0; i < oldCapacity ; i++) { // 遍历老数组 HashEntry<K,V> e = oldTable[i]; if (e != null) { HashEntry<K,V> next = e.next; // 计算新的位置,新的位置只可能是不变或者是老的位置+老的容量。 intidx= e.hash & sizeMask; if (next == null) // Single node on list // 如果当前位置还不是链表,只是一个元素,直接赋值 newTable[idx] = e; else { // Reuse consecutive sequence at same slot // 如果是链表了 HashEntry<K,V> lastRun = e; intlastIdx= idx; // 新的位置只可能是不变或者是老的位置+老的容量。 // 遍历结束后,lastRun 后面的元素位置都是相同的 for (HashEntry<K,V> last = next; last != null; last = last.next) { intk= last.hash & sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } // ,lastRun 后面的元素位置都是相同的,直接作为链表赋值到新位置。 newTable[lastIdx] = lastRun; // Clone remaining nodes for (HashEntry<K,V> p = e; p != lastRun; p = p.next) { // 遍历剩余元素,头插法到指定 k 位置。 Vv= p.value; inth= p.hash; intk= h & sizeMask; HashEntry<K,V> n = newTable[k]; newTable[k] = newHashEntry<K,V>(h, p.key, v, n); } } } } // 头插法插入新的节点 intnodeIndex= node.hash & sizeMask; // add the new node node.setNext(newTable[nodeIndex]); newTable[nodeIndex] = node; table = newTable; }
有些同学可能会对最后的两个 for 循环有疑惑,这里第一个 for 是为了寻找这样一个节点,这个节点后面的所有 next 节点的新位置都是相同的。然后把这个作为一个链表赋值到新位置。第二个 for 循环是为了把剩余的元素通过头插法插入到指定位置链表。这样实现的原因可能是基于概率统计,有深入研究的同学可以发表下意见。
内部第二个 for 循环中使用了 new HashEntry<K,V>(h, p.key, v, n) 创建了一个新的 HashEntry,而不是复用之前的,是因为如果复用之前的,那么会导致正在遍历(如正在执行 get 方法)的线程由于指针的修改无法遍历下去。正如注释中所说的:
当它们不再被可能正在并发遍历表的任何读取线程引用时,被替换的节点将被垃圾回收。
The nodes they replace will be garbage collectable as soon as they are no longer referenced by any reader thread that may be in the midst of concurrently traversing table
为什么需要再使用一个 for 循环找到 lastRun ,其实是为了减少对象创建的次数,正如注解中所说的:
从统计上看,在默认的阈值下,当表容量加倍时,只有大约六分之一的节点需要被克隆。
Statistically, at the default threshold, only about one-sixth of them need cloning when a table doubles.
get
到这里就很简单了,get 方法只需要两步即可。
计算得到 key 的存放位置。
遍历指定位置查找相同 key 的 value 值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
public V get(Object key) { Segment<K,V> s; // manually integrate access methods to reduce overhead HashEntry<K,V>[] tab; inth= hash(key); longu= (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; // 计算得到 key 的存放位置 if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) { for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { // 如果是链表,遍历查找到相同 key 的 value。 K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } returnnull; }