背包问题是一种经典的优化问题。有的时候我们需要将有一堆不同重量或者体积的物品放入背包,但是背包容量有限,这时就要寻找一种最优的物品组合,也就是让背包中的物品价值最大化或者重量最小化。
背包问题分为0/1背包问题和分数背包问题。
- 0/1背包问题是指在背包容量一定的情况下,每个物品只能选择放入背包一次或不放入,要求放入背包中的物品的总价值最大化或者总重量最小化。
- 分数背包问题是指在背包容量一定的情况下,每个物品可以选择放入部分或全部,要求放入背包中的物品的总价值最大化或者总重量最小化。
背包问题是一种经典的优化问题。有的时候我们需要将有一堆不同重量或者体积的物品放入背包,但是背包容量有限,这时就要寻找一种最优的物品组合,也就是让背包中的物品价值最大化或者重量最小化。
背包问题分为0/1背包问题和分数背包问题。
贪心算法(英语:greedy algorithm),又称贪婪算法,是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是最好或最优的算法。比如在旅行推销员问题中,如果旅行员每次都选择最近的城市,那这就是一种贪心算法。
贪心算法在有最优子结构的问题中尤为有效。最优子结构的意思是局部最优解能决定全局最优解。简单地说,问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。
贪心算法与动态规划的不同在于它对每个子问题的解决方案都做出选择,不能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行选择,有回退功能。
计数排序,它适用于数据量 n 较大但数据范围 m 较小的情况。假设我们需要对 n = 10^6 个学号进行排序,而学号是一个 8 位数字,这意味着数据范围 m = 10^8 非常大,使用计数排序需要分配大量内存空间,而基数排序可以避免这种情况。
「基数排序 Radix Sort」的核心思想与计数排序一致,也通过统计个数来实现排序。在此基础上,基数排序利用数字各位之间的递进关系,依次对每一位进行排序,从而得到最终的排序结果。
以学号数据为例,假设数字的最低位是第 1 位,最高位是第 8 位,基数排序的步骤如下:
前述的几种排序算法都属于“基于比较的排序算法”,它们通过比较元素间的大小来实现排序。此类排序算法的时间复杂度无法超越 O(n log n) 。接下来,我们将探讨几种“非比较排序算法”,它们的时间复杂度可以达到线性水平。
「桶排序 Bucket Sort」是分治思想的一个典型应用。它通过设置一些具有大小顺序的桶,每个桶对应一个数据范围,将数据平均分配到各个桶中;然后,在每个桶内部分别执行排序;最终按照桶的顺序将所有数据合并。
考虑一个长度为 n 的数组,元素是范围 [0, 1) 的浮点数。桶排序的流程如下:
「计数排序 Counting Sort」通过统计元素数量来实现排序,通常应用于整数数组。
先来看一个简单的例子。给定一个长度为 n 的数组 nums ,其中的元素都是“非负整数”。计数排序的整体流程如下:
counter ;counter 统计 nums 中各数字的出现次数,其中 counter[num] 对应数字 num 的出现次数。统计方法很简单,只需遍历 nums(设当前数字为 num),每轮将 counter[num] 增加 1 即可。「归并排序 Merge Sort」基于分治思想实现排序,包含“划分”和“合并”两个阶段:
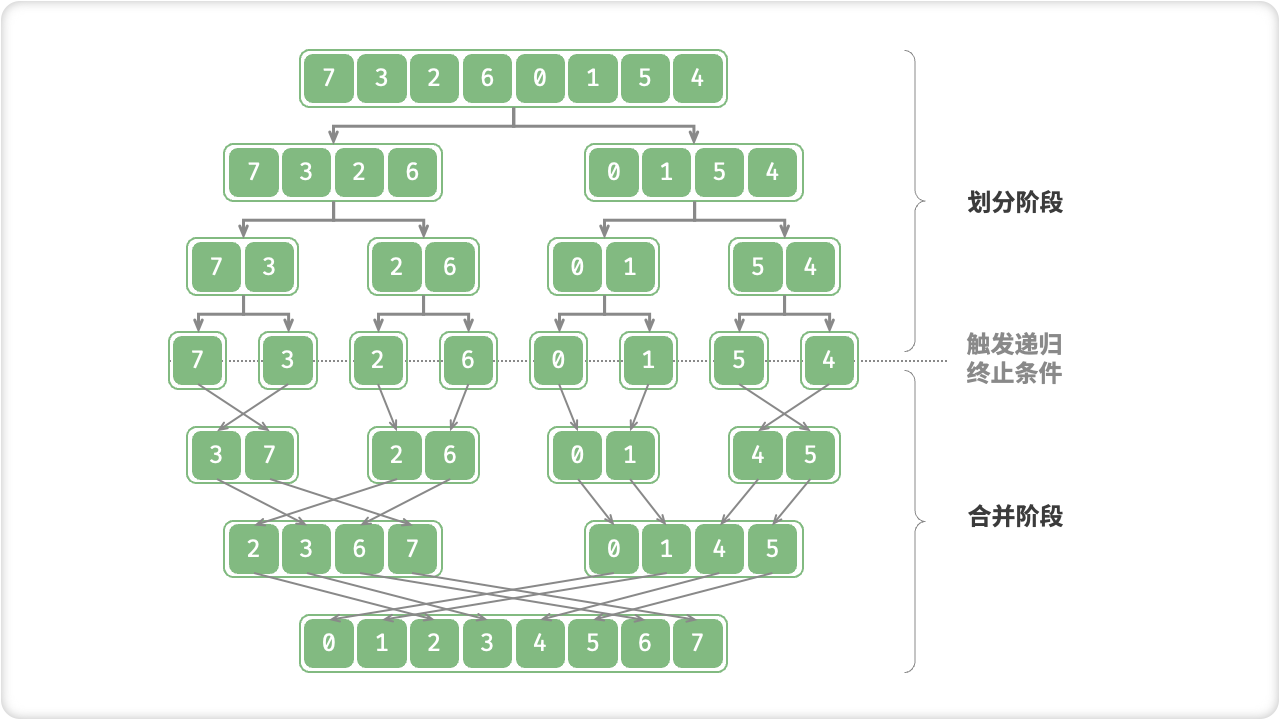
“划分阶段”从顶至底递归地将数组从中点切为两个子数组,直至长度为 1 ;
「堆排序 Heap Sort」是一种基于堆数据结构实现的高效排序算法。我们可以利用已经学过的“建堆操作”和“元素出堆操作”实现堆排序:
以上方法虽然可行,但需要借助一个额外数组来保存弹出的元素,比较浪费空间。在实际中,我们通常使用一种更加优雅的实现方式。
设数组的长度为 n ,堆排序的流程如下:
「快速排序 Quick Sort」是一种基于分治思想的排序算法,运行高效,应用广泛。
快速排序的核心操作是「哨兵划分」,其目标是:选择数组中的某个元素作为“基准数”,将所有小于基准数的元素移到其左侧,而大于基准数的元素移到其右侧。具体来说,哨兵划分的流程为:
i 和 j 分别指向数组的两端;i(j)分别寻找第一个比基准数大(小)的元素,然后交换这两个元素;2. ,直到 i 和 j 相遇时停止,最后将基准数交换至两个子数组的分界线;「插入排序 Insertion Sort」是一种简单的排序算法,它的工作原理与手动整理一副牌的过程非常相似。
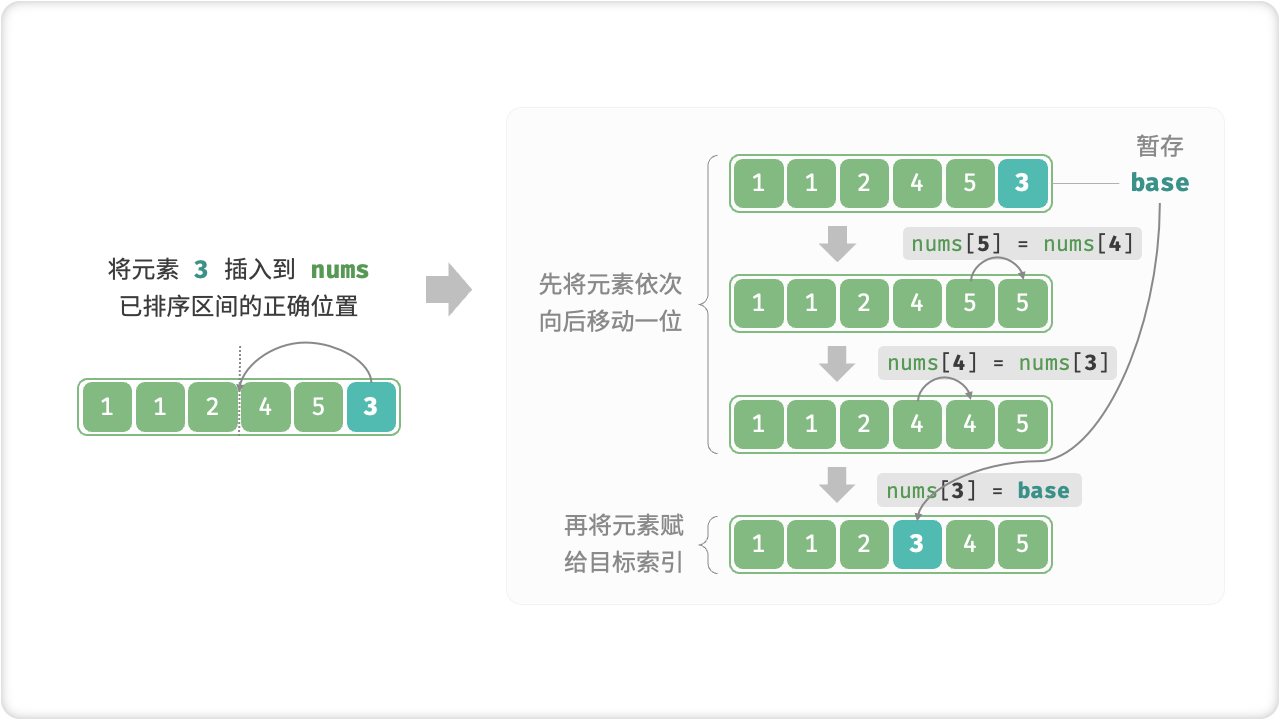
具体来说,我们在未排序区间选择一个基准元素,将该元素与其左侧已排序区间的元素逐一比较大小,并将该元素插入到正确的位置。
回忆数组的元素插入操作,设基准元素为 base ,我们需要将从目标索引到 base 之间的所有元素向右移动一位,然后再将 base 赋值给目标索引。
「选择排序 Selection Sort」的工作原理非常直接:开启一个循环,每轮从未排序区间选择最小的元素,将其放到已排序区间的末尾。
设数组的长度为 n ,选择排序的算法流程如下: