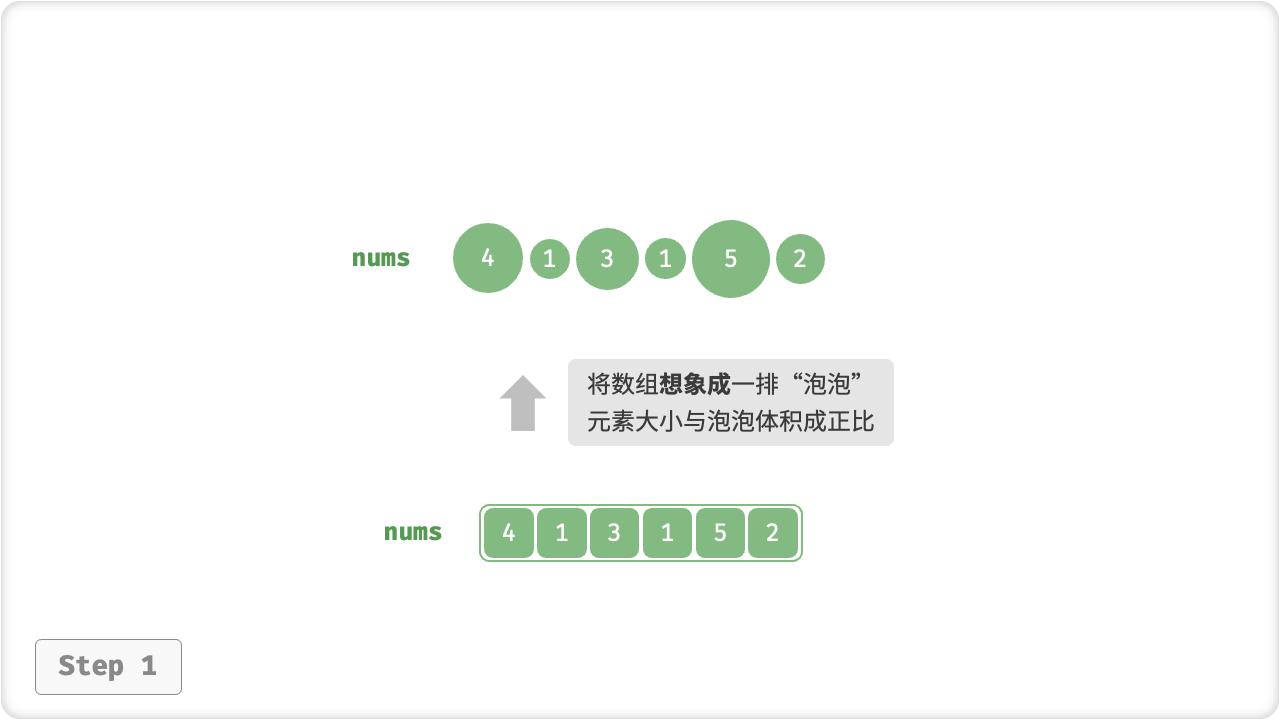
「冒泡排序 Bubble Sort」通过连续地比较与交换相邻元素实现排序。这个过程就像气泡从底部升到顶部一样,因此得名冒泡排序。
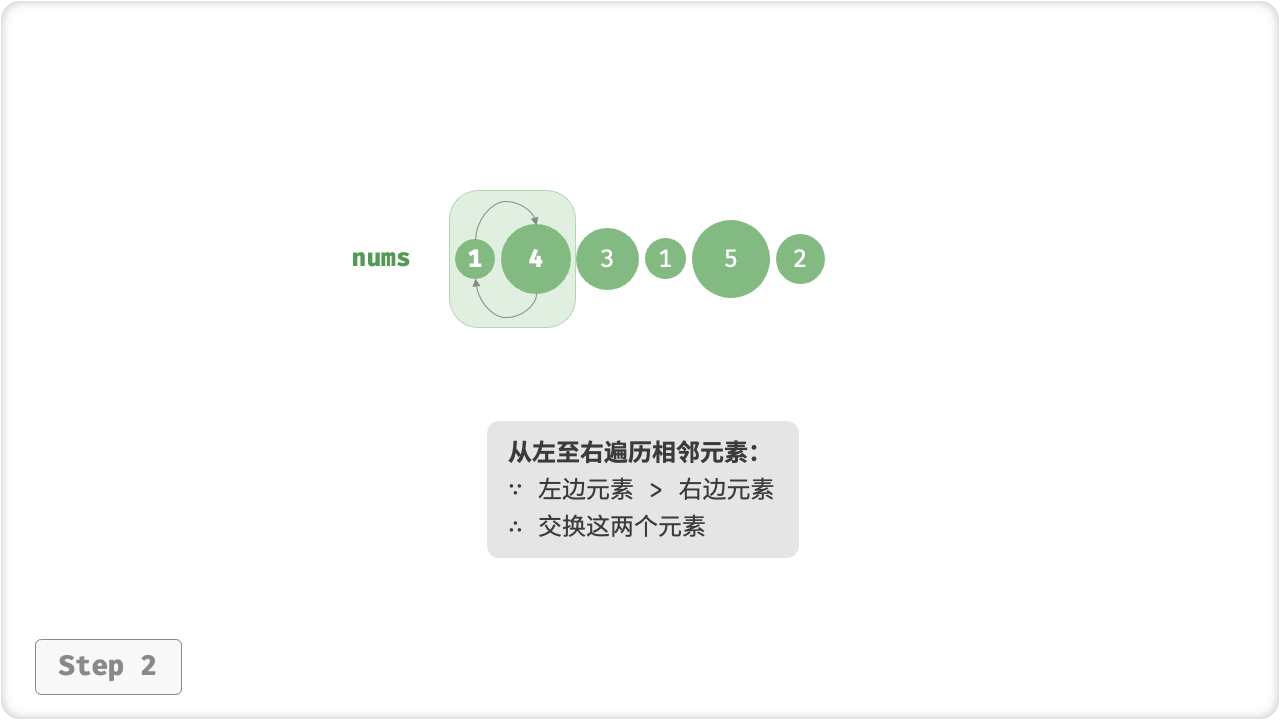
我们可以利用元素交换操作模拟上述过程:从数组最左端开始向右遍历,依次比较相邻元素大小,如果“左元素 > 右元素”就交换它俩。遍历完成后,最大的元素会被移动到数组的最右端。
1
2
「冒泡排序 Bubble Sort」通过连续地比较与交换相邻元素实现排序。这个过程就像气泡从底部升到顶部一样,因此得名冒泡排序。
我们可以利用元素交换操作模拟上述过程:从数组最左端开始向右遍历,依次比较相邻元素大小,如果“左元素 > 右元素”就交换它俩。遍历完成后,最大的元素会被移动到数组的最右端。
1
2
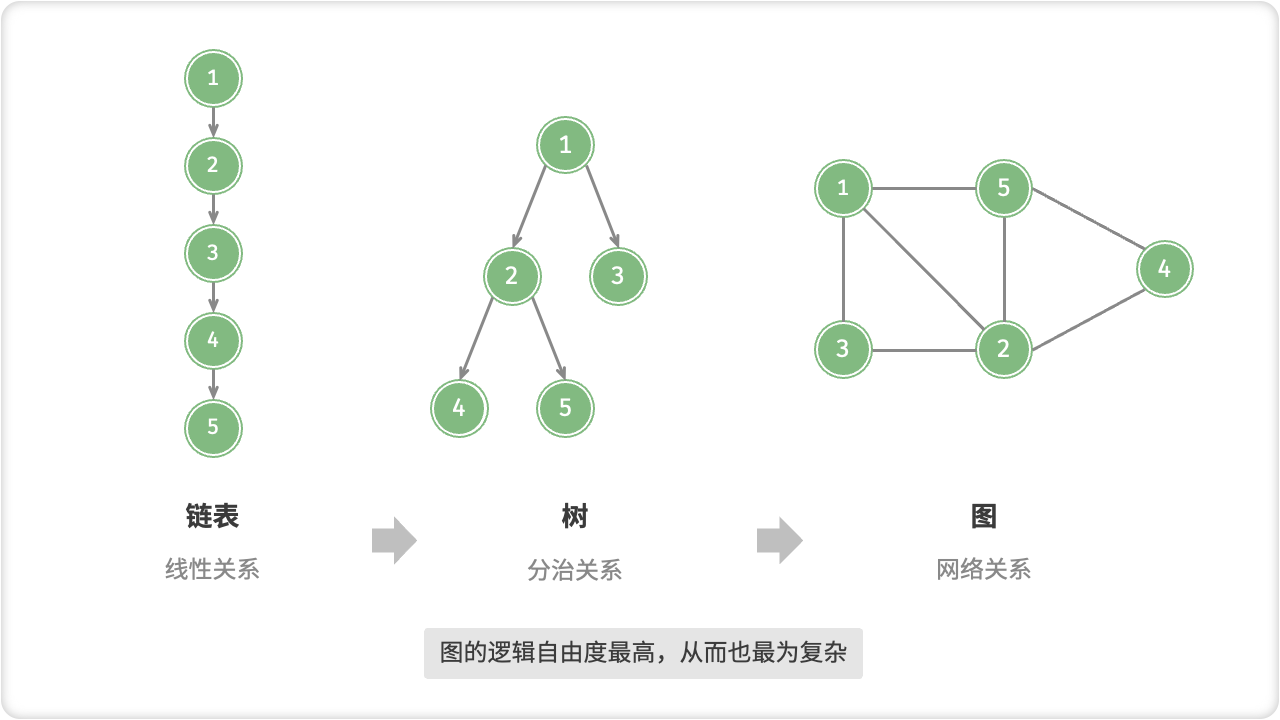
「图 Graph」是一种非线性数据结构,由「顶点 Vertex」和「边 Edge」组成。我们可以将图 G 抽象地表示为一组顶点 V 和一组边 E 的集合。以下示例展示了一个包含 5 个顶点和 7 条边的图。

「堆 Heap」是一种满足特定条件的完全二叉树,可分为两种类型:
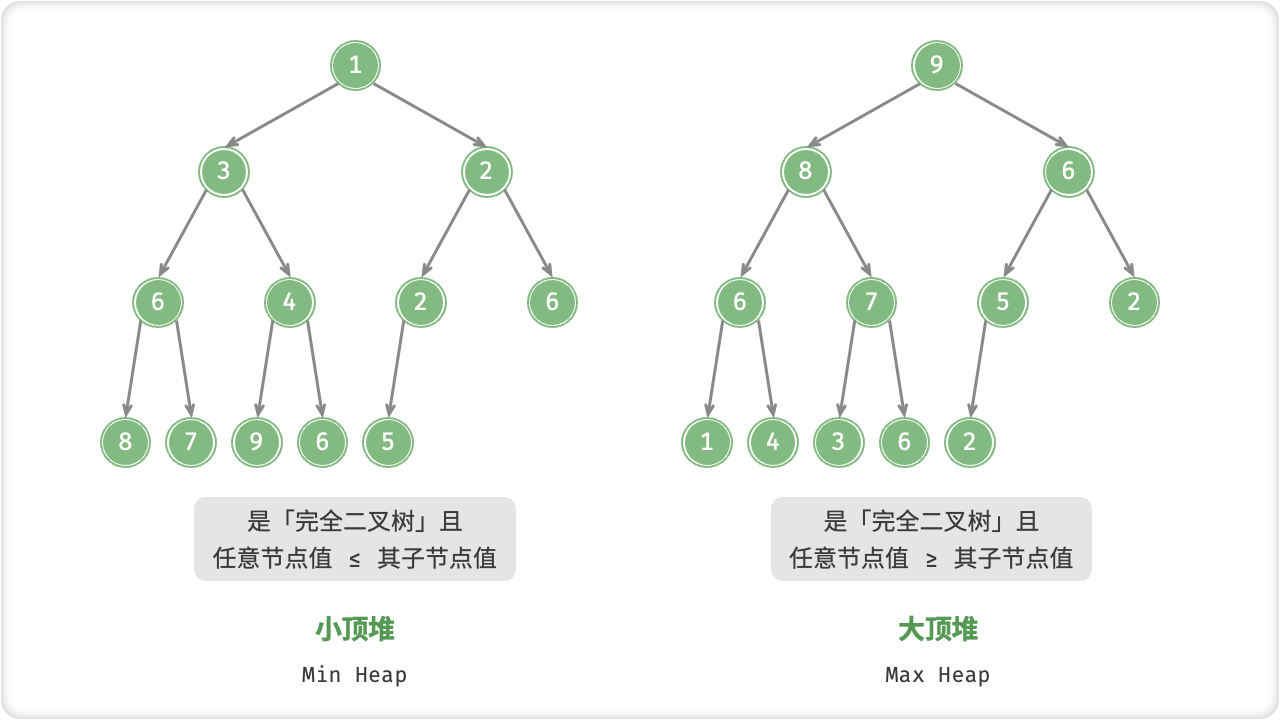
堆作为完全二叉树的一个特例,具有以下特性:
基于BST存在的问题,一种新的树——平衡二叉查找树(Balanced BST)产生了。平衡树在插入和删除的时候,会通过旋转操作将高度保持在logN。其中两款具有代表性的平衡树分别为AVL树和红黑树。AVL树由于实现比较复杂,而且插入和删除性能差,在实际环境下的应用不如红黑树。
红黑树(Red-Black Tree,以下简称RBTree)的实际应用非常广泛,比如Linux内核中的完全公平调度器、高精度计时器、ext3文件系统等等,各种语言的函数库如Java的TreeMap和TreeSet,C++ STL的map、multimap、multiset等。
RBTree也是函数式语言中最常用的持久数据结构之一,在计算几何中也有重要作用。值得一提的是,Java 8中HashMap的实现也因为用RBTree取代链表,性能有所提升。
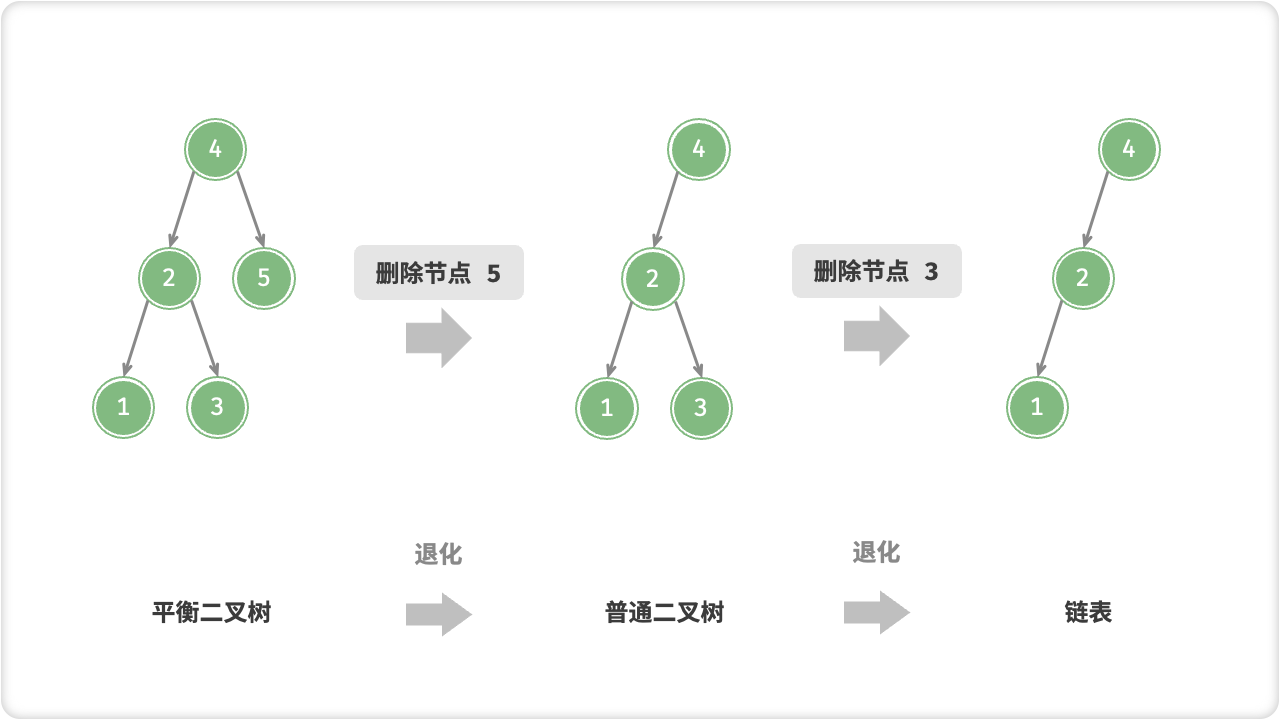
二叉搜索树可能在多次插入和删除操作后退化为链表。这种情况下,所有操作的时间复杂度将从 O(log n) 恶化为 O(n)。
如下图所示,经过两次删除节点操作,这个二叉搜索树便会退化为链表。
「二叉树 Binary Tree」是一种非线性数据结构,代表着祖先与后代之间的派生关系,体现着“一分为二”的分治逻辑。与链表类似,二叉树的基本单元是节点,每个节点包含一个「值」和两个「指针」。
节点的两个指针分别指向「左子节点」和「右子节点」,同时该节点被称为这两个子节点的「父节点」。当给定一个二叉树的节点时,我们将该节点的左子节点及其以下节点形成的树称为该节点的「左子树」,同理可得「右子树」。
在二叉树中,除叶节点外,其他所有节点都包含子节点和非空子树。例如,在以下示例中,若将“节点 2”视为父节点,则其左子节点和右子节点分别是“节点 4”和“节点 5”,左子树是“节点 4 及其以下节点形成的树”,右子树是“节点 5 及其以下节点形成的树”。
「二叉搜索树 Binary Search Tree」满足以下条件:
1. ;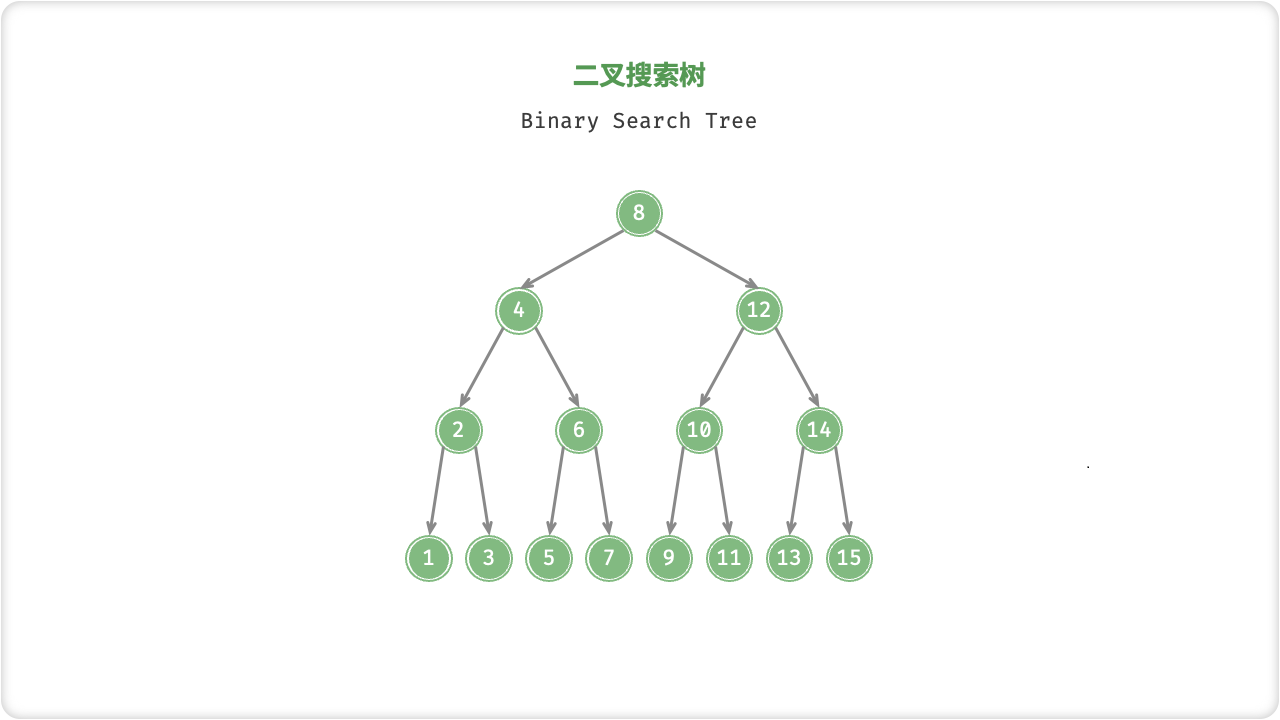
给定目标节点值 num ,可以根据二叉搜索树的性质来查找。我们声明一个节点 cur ,从二叉树的根节点 root 出发,循环比较节点值 cur.val 和 num 之间的大小关系
散列函数是这样的函数:不论你给它什么东西,它都返回给你一个数字;
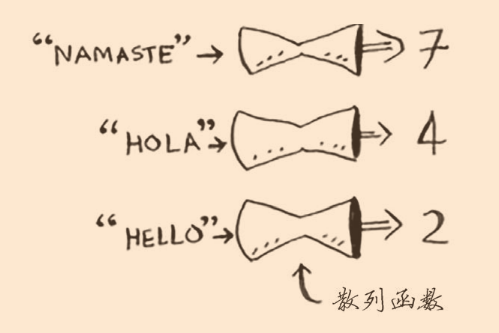
我们通过散列函数来创建一个空数组,给它什么输入,它就能给它特定的输出。比如先创建一个空数组,把apple当输入传给散列函数,函数返回3,那我们就可以把apple的价格比如4元存储到索引3处;
不断重复可以将这个数组填满,之后我们再向这个函数输入apple,它就会告诉我们价格存储在索引3处,时间复杂度为O(1);
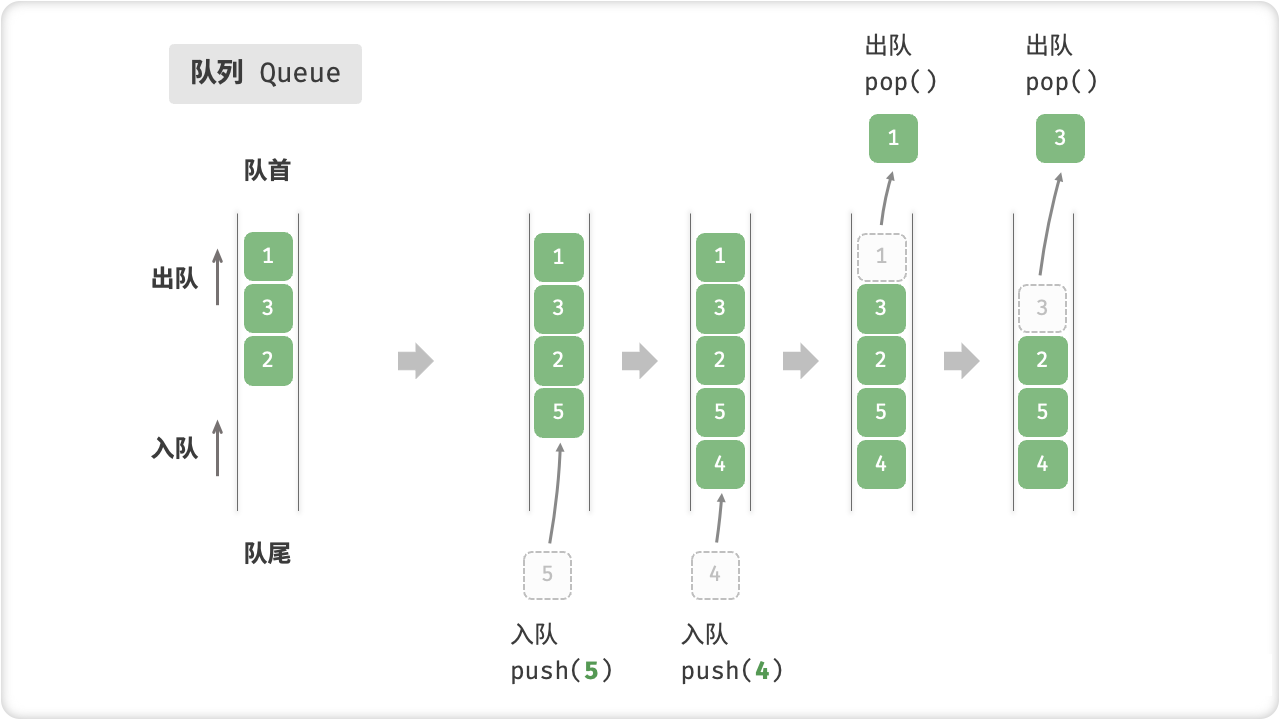
「队列 Queue」是一种遵循先入先出(First In, First Out)规则的线性数据结构。顾名思义,队列模拟了排队现象,即新来的人不断加入队列的尾部,而位于队列头部的人逐个离开。
我们把队列的头部称为「队首」,尾部称为「队尾」,把将元素加入队尾的操作称为「入队」,删除队首元素的操作称为「出队」。
队列的常见操作如下表所示。需要注意的是,不同编程语言的方法名称可能会有所不同。我们在此采用与栈相同的方法命名。