准备
SQL
1 | CREATE DATABASE test |
SQL
1 | CREATE DATABASE test |
前面已经学习了如何使用Spring与Struts2进行整合,本博文主要讲解如何使用Spring对Hibernate进行整合
Spring和Hibernate整合的关键点:
对象状态
Hibernate中对象的状态:
学习Hibernate的对象状态是为了更清晰地知道Hibernate的设计思想,以及是一级缓存的基础…当然啦,也就一点点知识
当我们直接new出来的对象就是临时/瞬时状态的..
在Hibernate的第二篇中只是简单地说了Hibernate的几种查询方式….到目前为止,我们都是使用一些简单的主键查询阿…使用HQL查询所有的数据….本博文主要讲解Hibernate的查询操作,连接池,逆向工程的知识点…
由于主键查询这个方法用得比较多,于是Hibernate专门为我们封装了起来…
前面的我们使用的是一个表的操作,但我们实际的开发中不可能只使用一个表的…因此,本博文主要讲解关联映射
需求分析:当用户购买商品,用户可能有多个地址。
我们一般如下图一样设计数据库表,一般我们不会在User表设计多个列来保存地址的。因为每个用户的地址个数都不一的,会造成数据冗余
Inverse属性:表示控制权是否转移..
Inverse属性,是在维护关联关系的时候起作用的。只能在“一”的一方中使用该属性!Inverse属性的默认值为fasle,也就是当前一方是有控制权的
本博文主要讲解介绍Hibernate框架,ORM的概念和Hibernate入门,相信你们看了就会使用Hibernate了!
Hibernate是一种ORM框架,全称为 Object_Relative DateBase-Mapping,在Java对象与关系数据库之间建立某种映射,以实现直接存取Java对象!
mybaits需要程序员自己编写sql语句,mybatis官方提供逆向工程,可以针对单表自动生成mybatis执行所需要的代码(mapper.java,mapper.xml、po..)
企业实际开发中,常用的逆向工程方式:由数据库的表生成java代码。
先附上官网链接:
我们系统为了提高系统并发,性能、一般对系统进行分布式部署(集群部署方式)
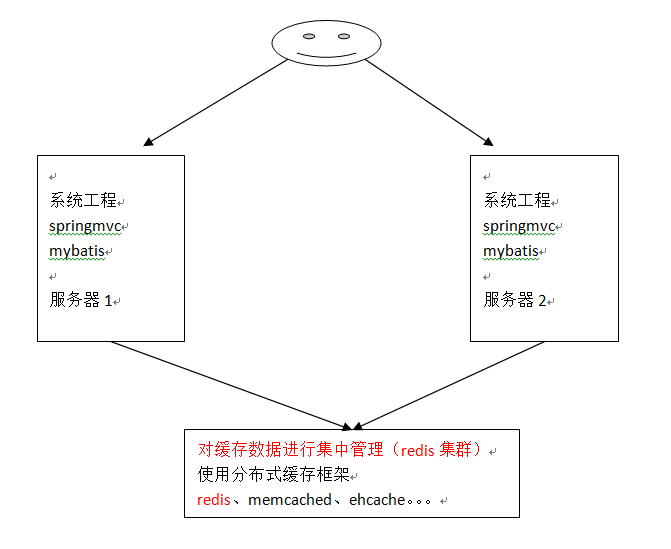
不使用分布缓存,缓存的数据在各各服务单独存储,不方便系统开发。所以要使用分布式缓存对缓存数据进行集中管理。
mybatis无法实现分布式缓存,需要和其它分布式缓存框架进行整合。
mybatis提供了一个cache接口,如果要实现自己的缓存逻辑,实现cache接口开发即可。
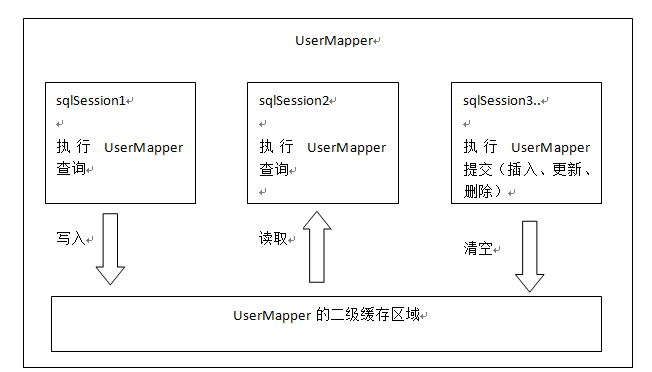
本文主要讲mybatis的二级缓存,二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。