Spring Cloud Alibaba Nacos 服务注册中心对比提升
各种服务注册中心对比
| 服务注册与发现框架 | CAP模型 | 控制台管理 | 社区活跃度 | |||
|---|---|---|---|---|---|---|
| Eureka | AP | 支持 | 低(2.x版本闭源) | |||
| Zookeeper | CP | 不支持 | 中 | |||
| Consul | 阅读更多
1 | <?xml version="1.0" encoding="UTF-8"?> |
Spring Cloud Alibaba Nacos 服务提供者注册
Nacos代替Eureka
Nacos可以直接提供注册中心(Eureka)+配置中心(Config),所以它的好处显而易见。Nacos本身就是一个小平台,它要比之前的Eureka更加方便,不需要我们在自己做配置。
Nacos服务注册中心
服务发现是微服务架构中的关键组件之一。在这样的架构中,手动为每个客户端配置服务列表可能是一项艰巨的任务,并且使得动态扩展极其困难。Nacos Discovery 帮助您自动将您的服务注册到 Nacos 服务器,Nacos 服务器会跟踪服务并动态刷新服务列表。此外,Nacos Discovery 将服务实例的一些元数据,如主机、端口、健康检查 URL、主页等注册到 Nacos。
,Martin Fowler(马丁·福勒 ) 提出了微服务的概念,定义了微服务是由以单一应用程序构成的小服务,自己拥有自己的进程与轻量化处理,服务依业务功能设计,以全自动的方式部署,与其他服务使用 HTTP API 通信。同时服务会使用最小的规模的集中管理能力,服务可以用不同的编程语言与数据库等组件实现。

马丁·福勒是敏捷联盟的成员,于2001年,同其他16名合著者一起协助创作了“敏捷软件开发宣言”。他负责维护一个bliki网站—一种blog和wiki的混合衍生物,他还使控制反转(Inversion of Control)“依赖注入模式(Dependency Injection)”一词得到普及。
Spring Cloud Alibaba Nacos 下载和安装
Nacos介绍
Nacos(Naming Configuration Service) 是一个易于使用的动态服务发现、配置和服务管理平台,用于构建云原生应用程序
服务发现是微服务架构中的关键组件之一。Nacos 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。
Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是构建以“服务”为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。
自定义消息通道
上篇文章我们提到了Sink和Source两个接口,这两个接口中分别定义了输入通道和输出通道,而Processor通过继承Source和Sink,同时具有输入通道和输出通道。这里我们就模仿Sink和Source,来定义一个自己的消息通道。
首先我们定义一个接口叫做MySink,如下:
1 | public interface MySink { |
创建工程
首先我们创建一个普通的Spring Boot工程,名为stream-hello,然后添加如下依赖:
1 | <dependency> |
结合RabbitMQ,可以实现配置文件动态刷新。我们先来看下面一张架构图:
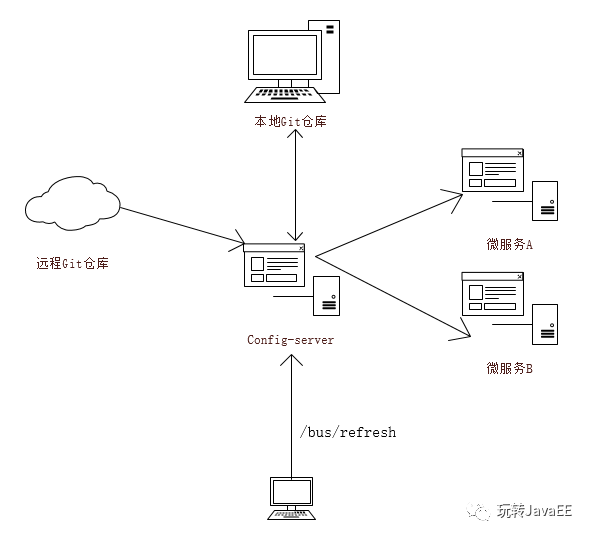
整张图的工作流程我们之前也详细的说过,当我的微服务A/微服务B启动的时候,会从Config-Server中加载配置文件,而Config-Server则会通过git clone命令将配置中心的配置文件先clone下来在本地保存一份,然后再返回给微服务A/微服务B。
这是我们之前的工作流程,现在我们结合Spring Cloud Bus来实现配置文件的动态更新。使用Spring Cloud Bus来实现配置文件的动态更新原理很简单,如上图,当我的配置文件更新后,我向Config-Server中发送一个/bus/refresh请求,Config-Server收到这个请求之后,会将这个请求广播出去,这样所有的微服务就都收到这个请求了,微服务收到这个请求之后就会自动去更新自己的配置文件。在这个系统中,从RabbitMQ的角度来看,所有的微服务都是一样的,所以这个/bus/refresh请求我们也可以在微服务节点上发出,一样能够实现配置文件动态更新的效果,但是这样做就破坏了我们微服务的结构,使得微服务节点之间有了区别,所以刷新配置的请求我们还是放在Config-Server上来做比较合适,好了,下面我们就来看看如何实现这一需求。
Kafka下载
Kafka现在是Apache上的开源项目,直接到官网下载即可(http://kafka.apache.org/),这个不用我多说。
启动
下载成功之后,是一个压缩文件,解压该文件,我们可以看到一个bin目录,进入到bin目录中,bin目录下的.sh文件都是Linux/Unix下的shell脚本,在Linux/Unix环境下直接运行这些脚本即可,bin目录中还有一个windows目录,该目录下存储的都是windows中的批处理文件。我们在运行时根据自己的操作系统选择合适的命令去执行,本文以windows为例。解压后为了后面的命令操作方便,我将windows文件配置到环境变量中,我的是D:\Program\kafka_2.11-0.11.0.1\bin\windows,然后在cmd中进入到解压目录下,执行zookeeper-server-start.bat .\config\zookeeper.properties命令,表示启动zookeeper(由于Kafka依赖的zookeeper,所以我们要先启动zookeeper再启动Kafka),如下:
Spring Cloud 实现 ZooKeeper 注册发现
一、配置虚拟机和 zookeeper
首先关闭 Linux 的防火墙:systemctl stop firewalld 然后可以使用 systemctl status firewalld 进行确认。
如果本机和虚拟机之间的网络连接方式为:NAT,则注意实际上连接
虚拟机终端输入ifconfig查看 ens33 下的端口号
查看主机与虚拟机之间通信是否畅通