简介
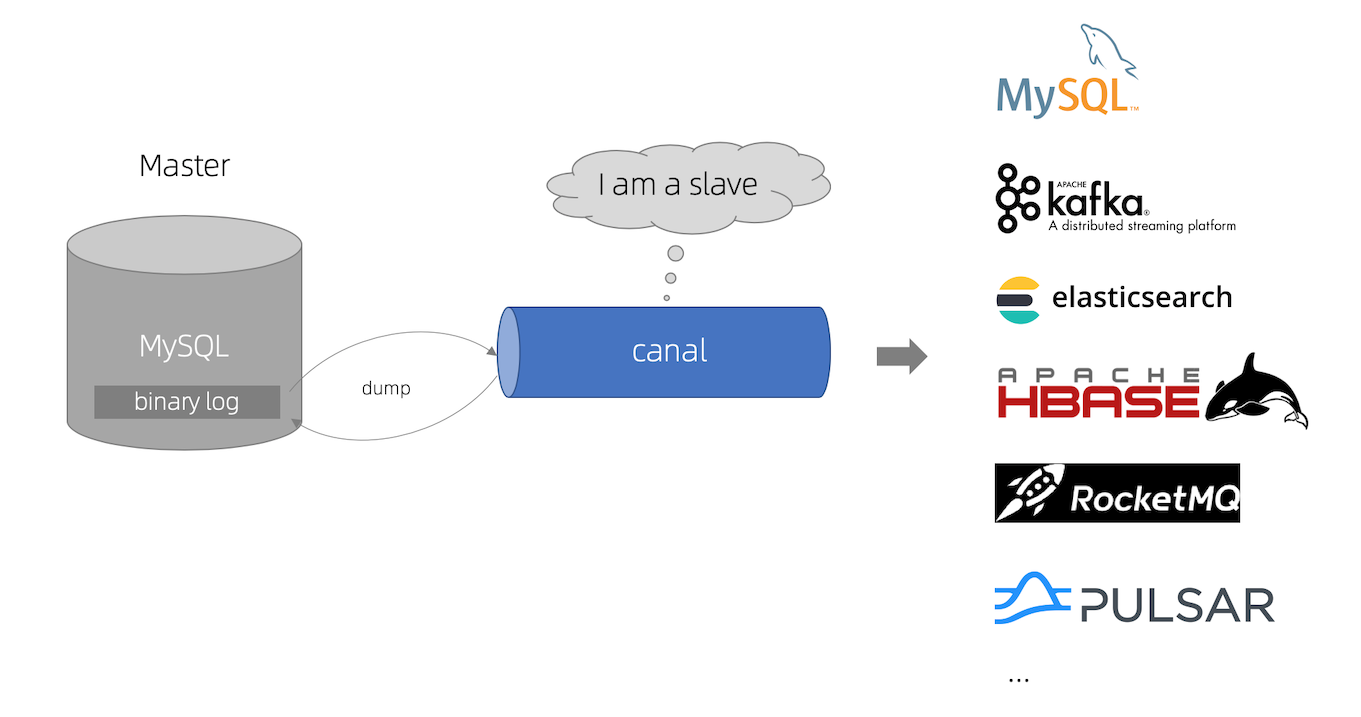
**canal [kə’næl]**,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
**canal [kə’næl]**,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
RabbitMQ 是一个开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用中间共享数据,RabbitMQ 是使用 Erlang 语言来编写的,并且 RabbitMQ 是基于 AMQP 协议的。
特点:
开源、性能优秀
Erlang 语言最初用在交换机的架构模式,这样使得 RabbitMQ 在 Broker 之间进行数据交互的性能时非常优秀的。Erlang 的优点:Erlang 有着和原生 Socket 一样的延迟。
新建 maven 项目或 module,添加 rocketmq-client 依赖。
1 |
|
1. 上传jdk压缩文件
将文件jdk-8u212-linux-x64.tar.gz上传到 /root 目录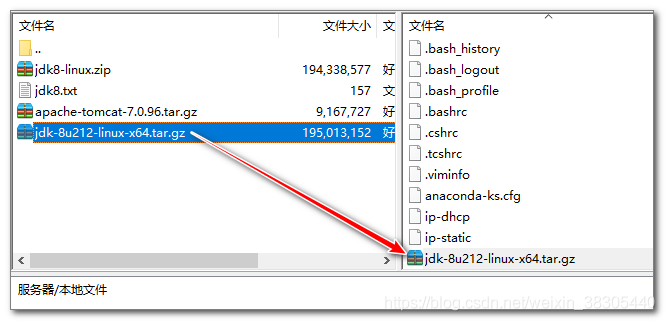
2. 解压缩
执行解压命令
1 | 将jdk解压到 /usr/local/ 目录 |
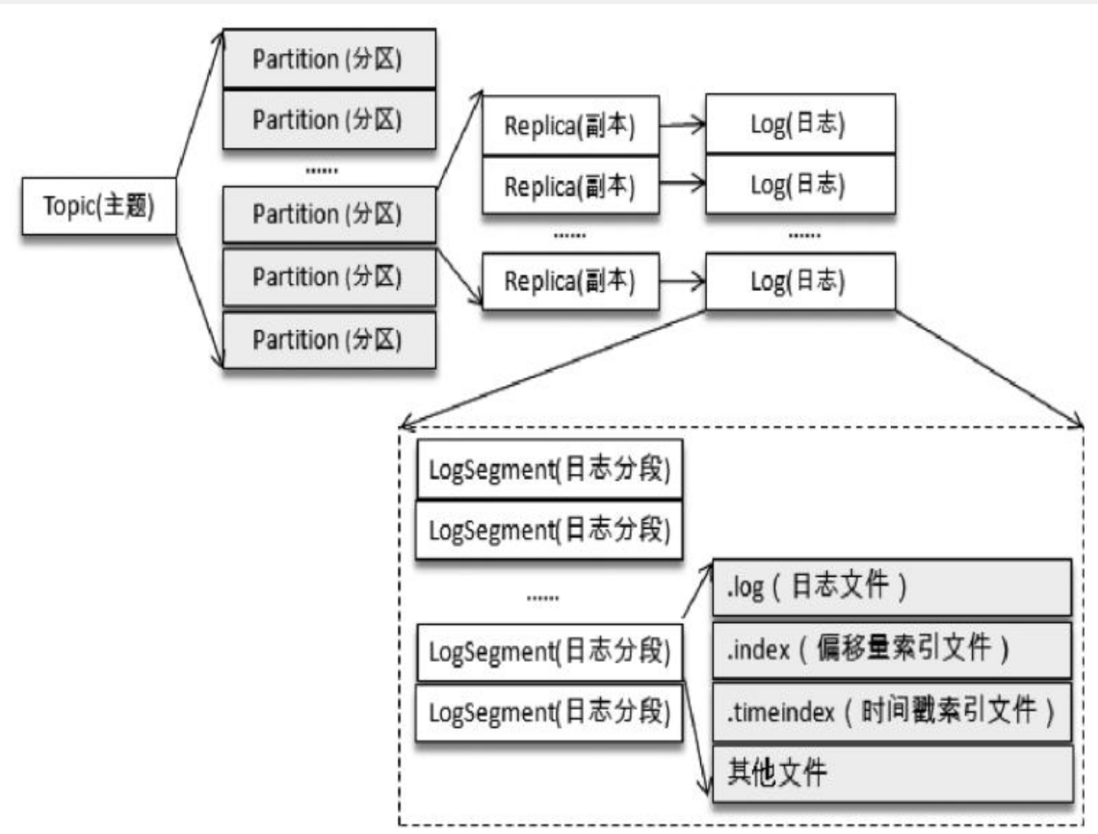
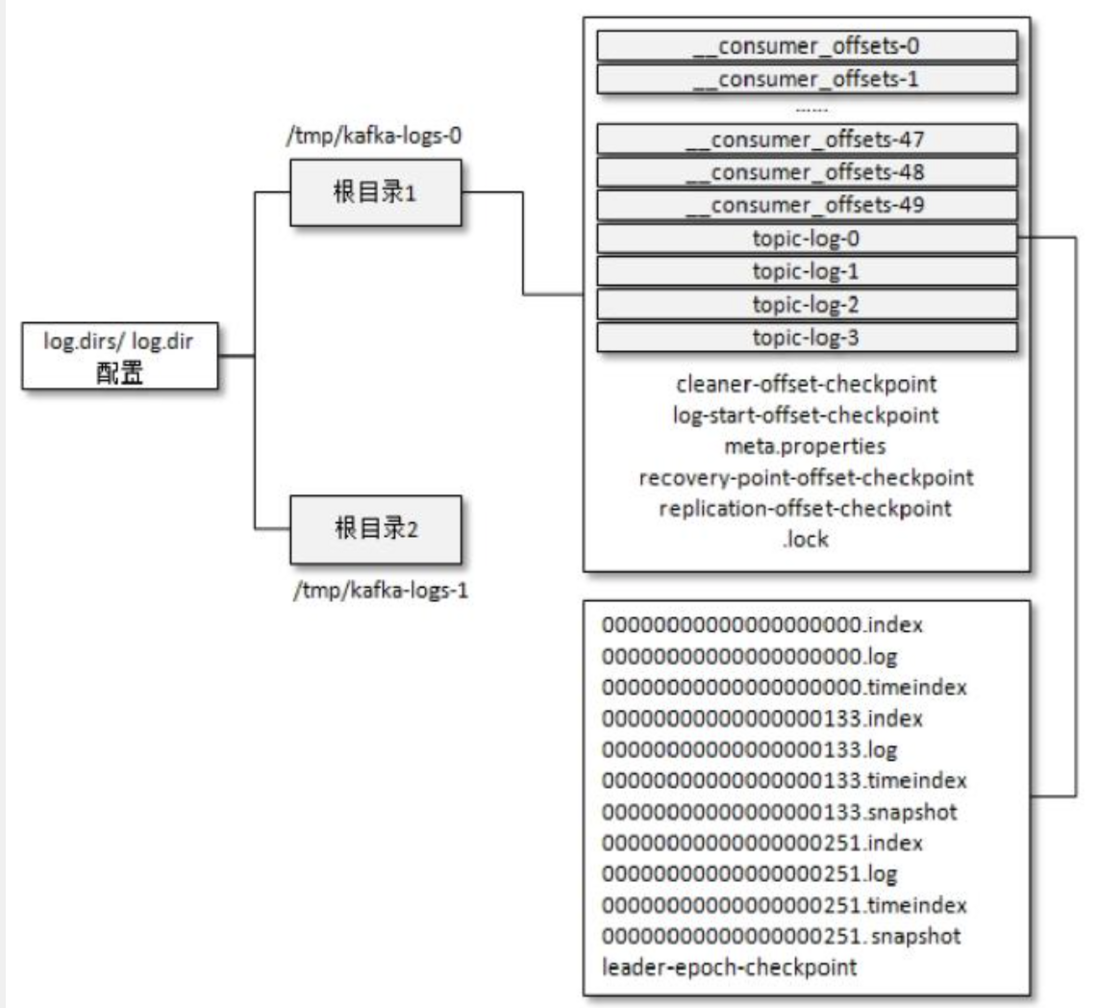
kafka 的索引文件以稀疏索引的方式构造消息的索引,每个 segmentfault 文件,对应 2 个索引文件。偏移量索引文件(xx.index)用于建立消息偏移量到物理地址之间的映射关系;时间戳索引文件(xx.timeindex)根据指定的时间戳查找对应的偏移量信息。
.index、.timeindex 均保持严格单调递增,在查找时,都使用二分查找法,如果查不到,均返回比查找值要小的最大值。
当日志分段文件满足以下几个条件任意之一,便会切分索引文件
kafka 允许通过配置 partition.assignment.strategy 来改变消费组的分区策略。kafka 提供了以下几个分区策略
RangeAssignorRoundRobinAssignorStickyAssignor默认使用的是 RangeAssignor
同时,kafka 也允许我们自定义分区策略,只需要继承 AbstractPartitionAssignor 抽象类即可。
1 | Properties prop = new Properties(); |