概述
分布式协调技术主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成”脏数据”的后果。
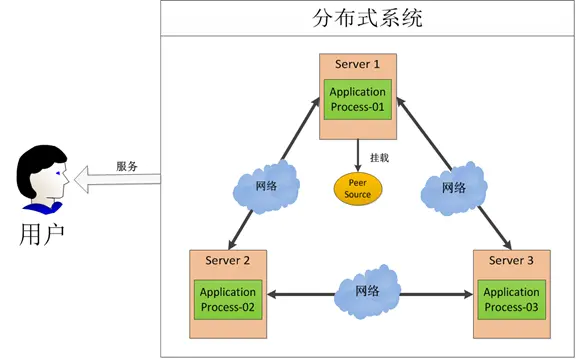
在这图中有三台机器,每台机器各跑一个应用程序。然后我们将这三台机器通过网络将其连接起来,构成一个系统来为用户提供服务,对用户来说这个系统的架构是透明的,他感觉不到我这个系统是一个什么样的架构。那么我们就可以把这种系统称作一个分布式系统。
分布式协调技术主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成”脏数据”的后果。
在这图中有三台机器,每台机器各跑一个应用程序。然后我们将这三台机器通过网络将其连接起来,构成一个系统来为用户提供服务,对用户来说这个系统的架构是透明的,他感觉不到我这个系统是一个什么样的架构。那么我们就可以把这种系统称作一个分布式系统。
一、ZK的最小配置
最小配置是指Zookeeper运行所需的最小配置,Zookeeper只需要配置这些项就可以正常的运行Zookeeper。
目前市场上主流的 第二套微服务架构解决方案:Spring Boot + Dubbo + Zookeeper
ZooKeeper 是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper 通过其简单的架构和 API 解决了这个问题。ZooKeeper 允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
在传统的单进程编程中,我们使用队列来存储一些数据结构,用来在多线程之间共享或传递数据。
分布式环境下,我们同样需要一个类似单进程队列的组件,用来实现跨进程、跨主机、跨网络的数据共享和数据传递,这就是我们的分布式队列。
zookeeper可以通过顺序节点实现分布式队列。
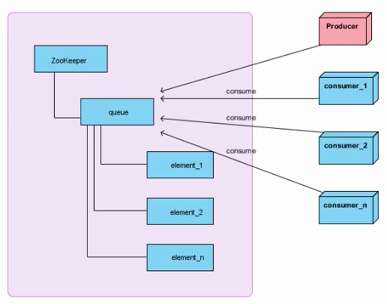
图中左侧代表zookeeper集群,右侧代表消费者和生产者。
生产者通过在queue节点下创建顺序节点来存放数据,消费者通过读取顺序节点来消费数据。
zookeeper的命名服务有两个应用方向,一个是提供类似JNDI的功能,利用zookeepeer的树型分层结构,可以把系统中各种服务的名称、地址以及目录信息存放在zookeeper,需要的时候去zookeeper中读取。
另一个,是利用zookeeper顺序节点的特性,制作分布式的ID生成器,写过数据库应用的朋友都知道,我们在往数据库表中插入记录时,通常需要为该记录创建唯一的ID,在单机环境中我们可以利用数据库的主键自增功能。但在分布式环境则无法使用,有一种方式可以使用UUID,但是它的缺陷是没有规律,很难理解。利用zookeeper顺序节点的特性,我们可以生成有顺序的,容易理解的,同时支持分布式环境的序列号。
1 | public class IdMaker { |
负载均衡是一种手段,用来把对某种资源的访问分摊给不同的设备,从而减轻单点的压力。
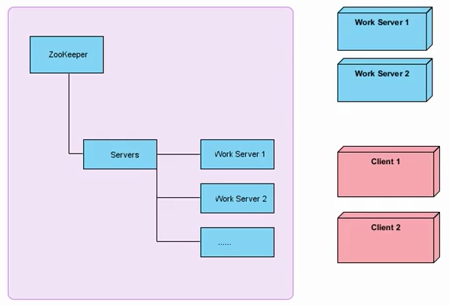
图中左侧为ZooKeeper集群,右侧上方为工作服务器,下面为客户端。每台工作服务器在启动时都会去zookeeper的servers节点下注册临时节点,每台客户端在启动时都会去servers节点下取得所有可用的工作服务器列表,并通过一定的负载均衡算法计算得出一台工作服务器,并与之建立网络连接。网络连接我们采用开源框架netty。
我们常说的锁是单进程多线程锁,在多线程并发编程中,用于线程之间的数据同步,保护共享资源的访问。而分布式锁,指在分布式环境下,保护跨进程、跨主机、跨网络的共享资源,实现互斥访问,保证一致性。
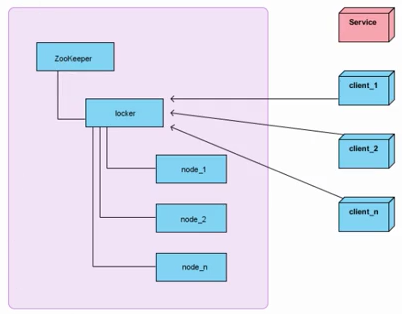
左侧是zookeeper集群,locker是数据节点,node_1到node_n代表一系列的顺序节点。
右侧client_1至client_n代表客户端,Service代表需要互斥访问的服务。
Apache ZooKeeper 是一个开源的实现高可用的分布式协调服务器。ZooKeeper是一种集中式服务,用于维护配置信息,域名服务,提供分布式同步和集群管理。所有这些服务的种类都被应用在分布式环境中,每一次实施这些都会做很多工作来避免出现bug和竞争条件。
ZooKeeper 允许分布式进程通过共享的分层命名空间相互协调,ZooKeeper命名空间与文件系统很相似,每个命名空间填充了数据节点的注册信息 - 叫做Znode,这是在 ZooKeeper 中的叫法,Znode 很像我们文件系统中的文件和目录。ZooKeeper 与典型的文件系统不同,ZooKeeper 数据保存在内存中,这意味着 ZooKeeper 可以实现高吞吐量和低时延。
多个订阅者对象同时监听同一主题对象,主题对象状态变化时通知所有订阅者对象更新自身状态。发布方和订阅方独立封装、独立改变,当一个对象的改变需要同时改变其他对象,并且它不知道有多少个对象需要改变时,可以使用发布订阅模式。
在分布式系统中的顶级应用有配置管理和服务发现。
配置管理:指集群中的机器拥有某些配置,并且这些配置信息需要动态地改变,那么我们就可以使用发布订阅模式把配置做统一的管理,让这些机器订阅配置信息的改变,但是配置改变时这些机器得到通知并更新自己的配置。
服务发现:指对集群中的服务上下线做统一管理,每个工作服务器都可以作为数据的发布方,向集群注册自己的基本信息,而让某些监控服务器作为订阅方,订阅工作服务器的基本信息。当工作服务器的基本信息改变时,如服务上下线、服务器的角色或服务范围变更,那么监控服务器可以得到通知并响应这些变化。