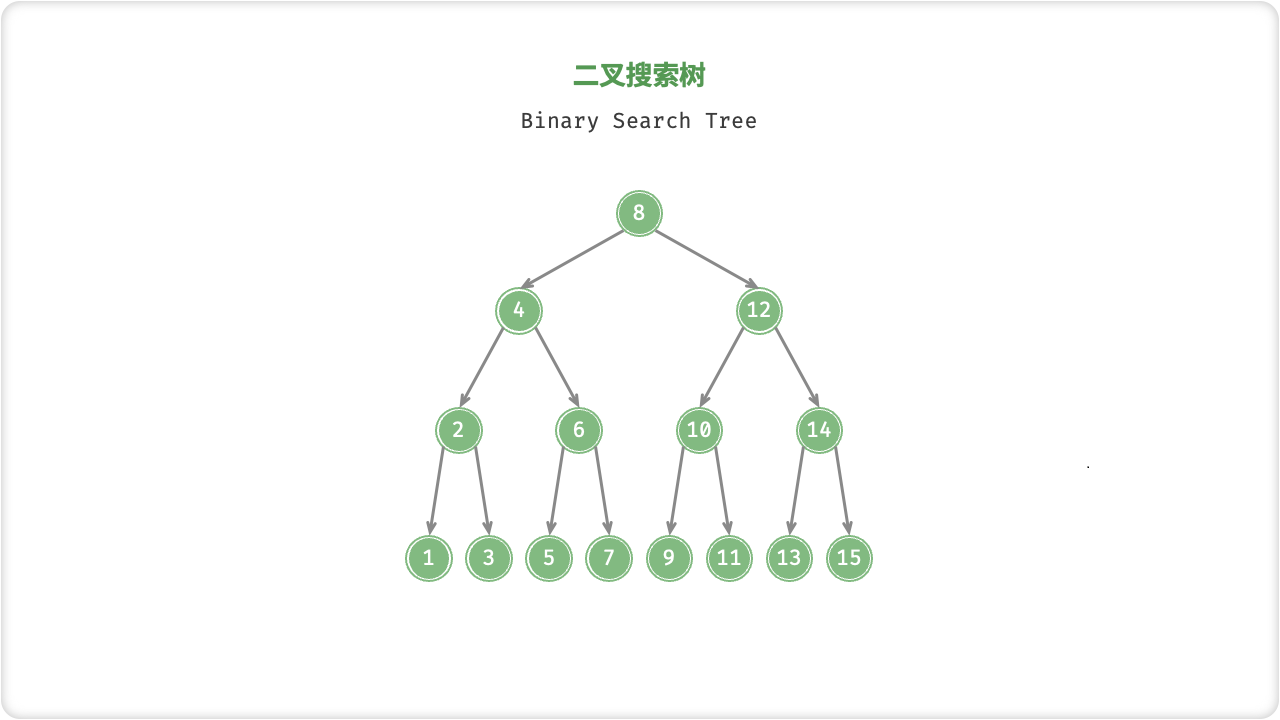
「二叉搜索树 Binary Search Tree」满足以下条件:
- 对于根节点,左子树中所有节点的值 < 根节点的值 < 右子树中所有节点的值;
- 任意节点的左、右子树也是二叉搜索树,即同样满足条件
1.;
二叉搜索树的操作
查找节点
给定目标节点值 num ,可以根据二叉搜索树的性质来查找。我们声明一个节点 cur ,从二叉树的根节点 root 出发,循环比较节点值 cur.val 和 num 之间的大小关系
「二叉搜索树 Binary Search Tree」满足以下条件:
1. ;
给定目标节点值 num ,可以根据二叉搜索树的性质来查找。我们声明一个节点 cur ,从二叉树的根节点 root 出发,循环比较节点值 cur.val 和 num 之间的大小关系
散列函数是这样的函数:不论你给它什么东西,它都返回给你一个数字;
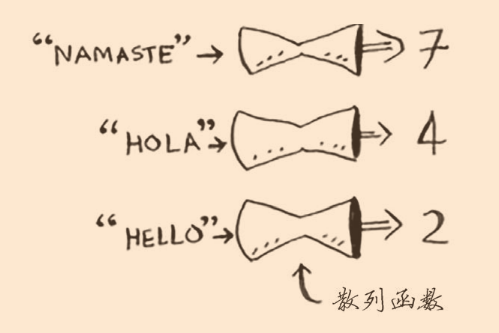
我们通过散列函数来创建一个空数组,给它什么输入,它就能给它特定的输出。比如先创建一个空数组,把apple当输入传给散列函数,函数返回3,那我们就可以把apple的价格比如4元存储到索引3处;
不断重复可以将这个数组填满,之后我们再向这个函数输入apple,它就会告诉我们价格存储在索引3处,时间复杂度为O(1);
「队列 Queue」是一种遵循先入先出(First In, First Out)规则的线性数据结构。顾名思义,队列模拟了排队现象,即新来的人不断加入队列的尾部,而位于队列头部的人逐个离开。
我们把队列的头部称为「队首」,尾部称为「队尾」,把将元素加入队尾的操作称为「入队」,删除队首元素的操作称为「出队」。
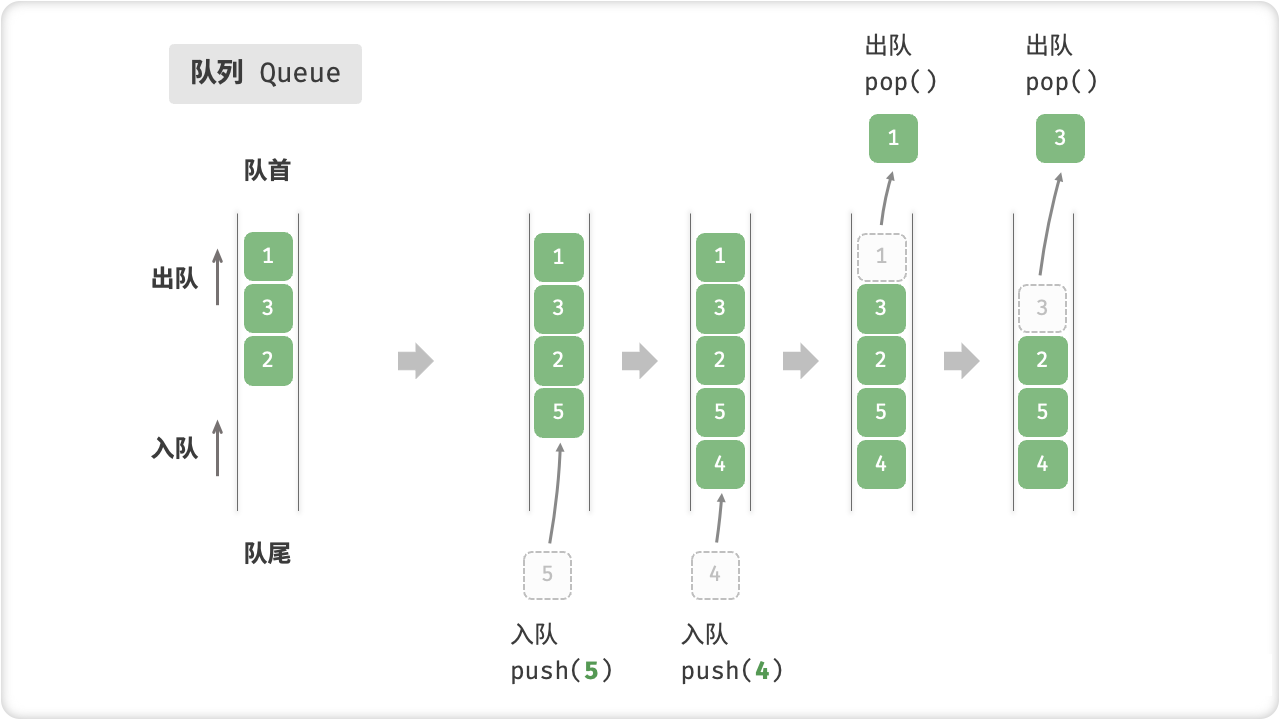
队列的常见操作如下表所示。需要注意的是,不同编程语言的方法名称可能会有所不同。我们在此采用与栈相同的方法命名。
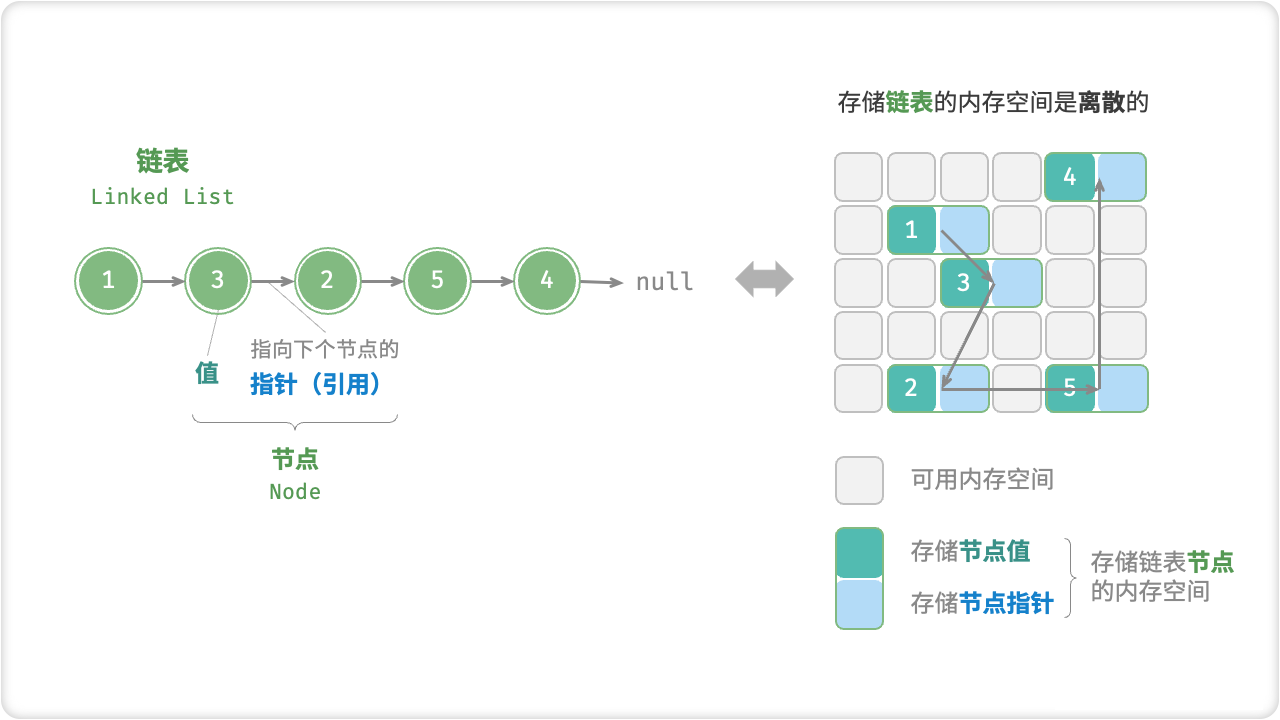
**链表(Linked List)**也是线性结构,它与数组看起来非常像,但是它们的内存分配方式、内部结构和插入删除操作方式都不一样。
链表是一系列节点组成的链,每一个节点保存了数据以及指向下一个节点的指针。链表头指针指向第一个节点,如果链表为空,则头指针为空或者为null。
链表「节点 Node」包含两项数据,一是节点「值 Value」,二是指向下一节点的「指针 Pointer」,或称「引用 Reference」。
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。
像 Java 中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
1 | public void performSynchronisedTask() { |
「栈 Stack」是一种遵循先入后出(First In, Last Out)原则的线性数据结构。
我们可以将栈类比为桌面上的一摞盘子,如果需要拿出底部的盘子,则需要先将上面的盘子依次取出。我们将盘子替换为各种类型的元素(如整数、字符、对象等),就得到了栈数据结构。
在栈中,我们把堆叠元素的顶部称为「栈顶」,底部称为「栈底」。将把元素添加到栈顶的操作叫做「入栈」,而删除栈顶元素的操作叫做「出栈」。
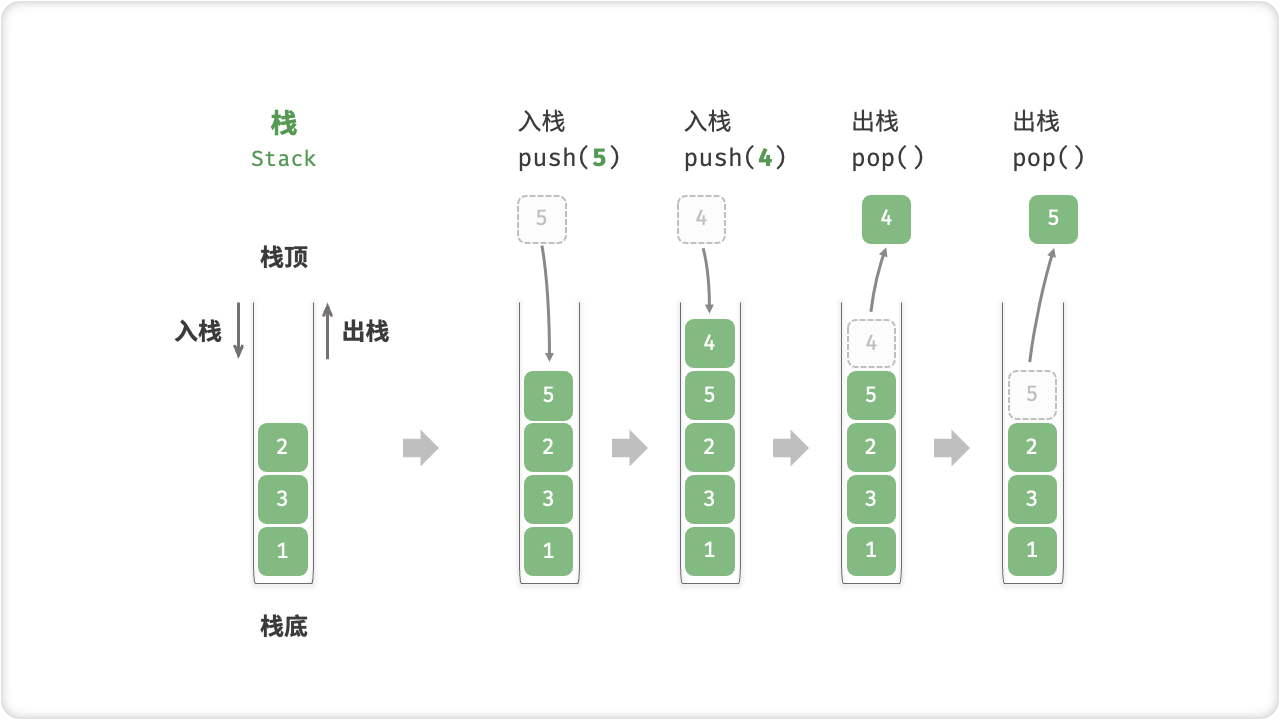
栈的常用操作如下表所示,具体的方法名需要根据所使用的编程语言来确定。在此,我们以常见的 push() , pop() , peek() 命名为例。
数组长度不可变导致实用性降低。在许多情况下,我们事先无法确定需要存储多少数据,这使数组长度的选择变得困难。若长度过小,需要在持续添加数据时频繁扩容数组;若长度过大,则会造成内存空间的浪费。
为解决此问题,出现了一种被称为「动态数组 Dynamic Array」的数据结构,即长度可变的数组,也常被称为「列表 List」。列表基于数组实现,继承了数组的优点,并且可以在程序运行过程中动态扩容。在列表中,我们可以自由添加元素,而无需担心超过容量限制。
初始化列表。通常我们会使用“无初始值”和“有初始值”的两种初始化方法。
**数组(Array)**大概是最简单,也是最常用的数据结构了。其他数据结构,比如栈和队列都是由数组衍生出来的。
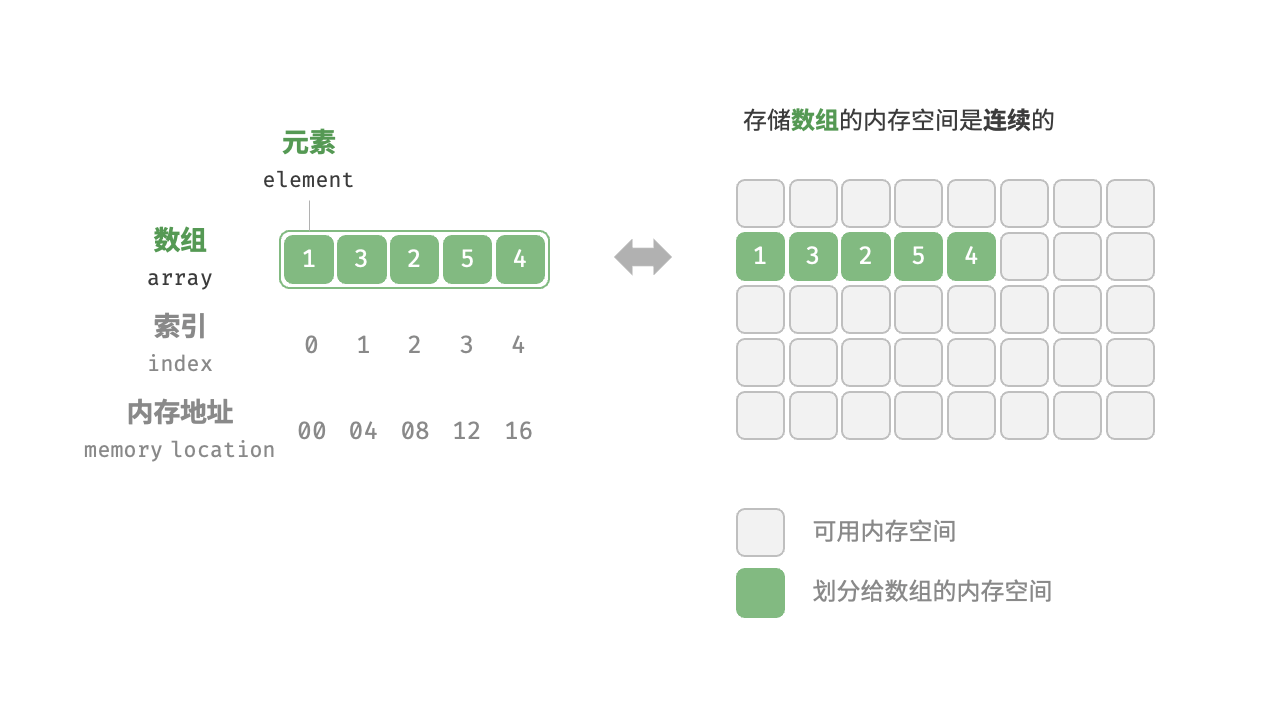
每一个数组元素的位置由数字编号,称为下标或者索引(index)。大多数编程语言的数组第一个元素的下标是0。
根据维度区分,有2种不同的数组: