InnoDB如何引擎通过Next-Key Lock部分解决幻读
1. 幻读问题概述
幻读是数据库并发事务中最棘手的一类问题。它指在同一事务内,连续执行两次相同的查询语句,第二次查询所返回的结果集与第一次查询的结果集不同。具体表现为:新增了符合查询条件的行。
示例场景
1 | -- 事务A |
InnoDB如何引擎通过Next-Key Lock部分解决幻读
幻读是数据库并发事务中最棘手的一类问题。它指在同一事务内,连续执行两次相同的查询语句,第二次查询所返回的结果集与第一次查询的结果集不同。具体表现为:新增了符合查询条件的行。
1 | -- 事务A |
在并发环境下,多个事务同时操作数据库时会产生各种并发问题。如果不进行隔离控制,可能会导致数据的不一致性。主要会出现以下问题:
堆是一种特殊的完全二叉树,分为大根堆(大顶堆)和小根堆(小顶堆):
堆通常用数组实现,对于数组中的第i个节点:
下面是一个小根堆的Java实现:
Java 阻塞队列的历史可以追溯到 JDK1.5 版本,当时 Java 平台增加了 java.util.concurrent,即我们常说的 JUC 包,其中包含了各种并发流程控制工具、并发容器、原子类等。这其中自然也包含了我们这篇文章所讨论的阻塞队列。
为了解决高并发场景下多线程之间数据共享的问题,JDK1.5 版本中出现了 ArrayBlockingQueue 和 LinkedBlockingQueue,它们是带有生产者-消费者模式实现的并发容器。其中,ArrayBlockingQueue 是有界队列,即添加的元素达到上限之后,再次添加就会被阻塞或者抛出异常。而 LinkedBlockingQueue 则由链表构成的队列,正是因为链表的特性,所以 LinkedBlockingQueue 在添加元素上并不会向 ArrayBlockingQueue 那样有着较多的约束,所以 LinkedBlockingQueue 设置队列是否有界是可选的(注意这里的无界并不是指可以添加任务数量的元素,而是说队列的大小默认为 Integer.MAX_VALUE,近乎于无限大)。
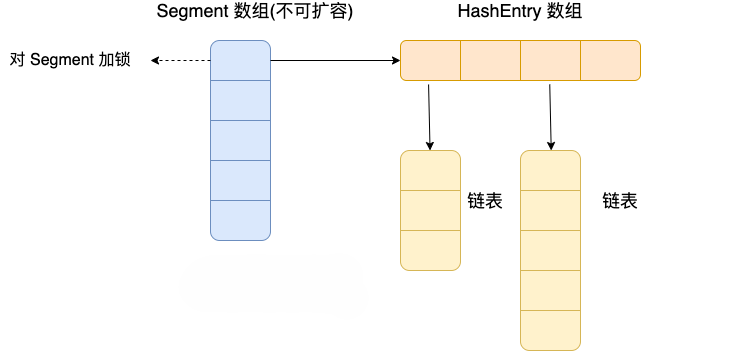
Java 7 中 ConcurrentHashMap 的存储结构如上图,ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦初始化就不能改变,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。
《阿里巴巴 Java 开发手册》的描述如下:
判断所有集合内部的元素是否为空,使用
isEmpty()方法,而不是size()==0的方式。
这是因为 isEmpty() 方法的可读性更好,并且时间复杂度为 O(1)。
绝大部分我们使用的集合的 size() 方法的时间复杂度也是 O(1),不过,也有很多复杂度不是 O(1) 的,比如 java.util.concurrent 包下的 ConcurrentLinkedQueue。ConcurrentLinkedQueue 的 isEmpty() 方法通过 first() 方法进行判断,其中 first() 方法返回的是队列中第一个值不为 null 的节点(节点值为null的原因是在迭代器中使用的逻辑删除)
双指针是一种重要的算法技巧,使用两个指针对数组或链表进行操作。
对撞指针是指两个指针从数组的两端向中间移动。
给定一个已按照升序排列的数组,找出两个数使得它们的和等于目标数。
1 | public int[] twoSum(int[] nums, int target) { |
开始介绍类加载器和双亲委派模型之前,简单回顾一下类加载过程。
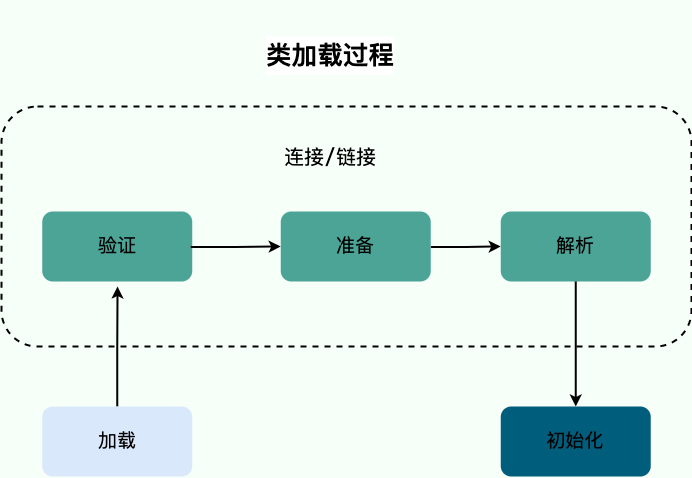
加载是类加载过程的第一步,主要完成下面 3 件事情:
使用 Spring Boot + Javassist 实现运行时动态添加和删除 Controller
在某些特殊场景下,我们可能需要在 Spring Boot 应用运行时动态地添加或删除 Controller。本文将详细介绍如何使用 Javassist 和 Spring Boot 的内部机制来实现这个功能。
1 | <parent> |