介绍
1.单机、单实例的持久化方式
1 | rdb(relation-ship database)持久化: |
1 | rdb(relation-ship database)持久化: |
redis是单线程,单实例,为什么并发那么多,依旧很快呢?
回答:因为调用了系统内核的epoll
Linux有Linux kernal,我们的客户端,进行连接,首先到达的是Linux kernal,在Linux的早期版本,只有read和write进行文件读写。我们使用一个线程/进程 进行调用read和write函数,那么将会返回一个文件描述符fd(file description)。我们开启线程/进程去调用read进行读取。因为socket在这个时期是blocking(阻塞的),遇到高并发,就会阻塞,也就是bio时期。
很久之前,我们的数据存储方式是磁盘存储,每个磁盘都有一个磁道。每个磁道有很多扇区,一个扇区接近512Byte。
磁盘的寻址速度是毫秒级的,带宽是GB/M的。内存是ns级的,带宽也比磁盘大上好几个数量级。总体来说,磁盘比内存在寻址上慢了接近10W倍。
在这段历史中,我们的面临的问题是,I/O问题。在读写文件时,我们常常面临很大的I/O成本问题。但是最初有个最初的解决方案是加一个buffer。
上篇文章我们提到了Sink和Source两个接口,这两个接口中分别定义了输入通道和输出通道,而Processor通过继承Source和Sink,同时具有输入通道和输出通道。这里我们就模仿Sink和Source,来定义一个自己的消息通道。
首先我们定义一个接口叫做MySink,如下:
1 | public interface MySink { |
首先我们创建一个普通的Spring Boot工程,名为stream-hello,然后添加如下依赖:
1 | <dependency> |
结合RabbitMQ,可以实现配置文件动态刷新。我们先来看下面一张架构图:
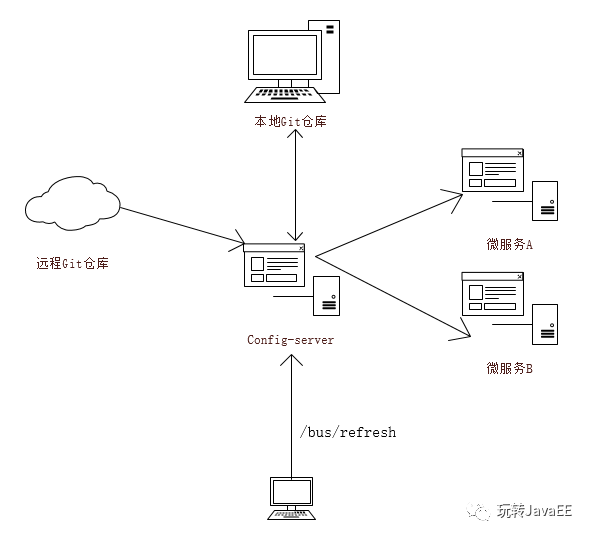
整张图的工作流程我们之前也详细的说过,当我的微服务A/微服务B启动的时候,会从Config-Server中加载配置文件,而Config-Server则会通过git clone命令将配置中心的配置文件先clone下来在本地保存一份,然后再返回给微服务A/微服务B。
这是我们之前的工作流程,现在我们结合Spring Cloud Bus来实现配置文件的动态更新。使用Spring Cloud Bus来实现配置文件的动态更新原理很简单,如上图,当我的配置文件更新后,我向Config-Server中发送一个/bus/refresh请求,Config-Server收到这个请求之后,会将这个请求广播出去,这样所有的微服务就都收到这个请求了,微服务收到这个请求之后就会自动去更新自己的配置文件。在这个系统中,从RabbitMQ的角度来看,所有的微服务都是一样的,所以这个/bus/refresh请求我们也可以在微服务节点上发出,一样能够实现配置文件动态更新的效果,但是这样做就破坏了我们微服务的结构,使得微服务节点之间有了区别,所以刷新配置的请求我们还是放在Config-Server上来做比较合适,好了,下面我们就来看看如何实现这一需求。
Arrays 是针对数组进行操作的工具类。
1 | public static String toString(int[] a) //把数组转成字符串 |
Kafka现在是Apache上的开源项目,直接到官网下载即可(http://kafka.apache.org/),这个不用我多说。
下载成功之后,是一个压缩文件,解压该文件,我们可以看到一个bin目录,进入到bin目录中,bin目录下的.sh文件都是Linux/Unix下的shell脚本,在Linux/Unix环境下直接运行这些脚本即可,bin目录中还有一个windows目录,该目录下存储的都是windows中的批处理文件。我们在运行时根据自己的操作系统选择合适的命令去执行,本文以windows为例。解压后为了后面的命令操作方便,我将windows文件配置到环境变量中,我的是D:\Program\kafka_2.11-0.11.0.1\bin\windows,然后在cmd中进入到解压目录下,执行zookeeper-server-start.bat .\config\zookeeper.properties命令,表示启动zookeeper(由于Kafka依赖的zookeeper,所以我们要先启动zookeeper再启动Kafka),如下: